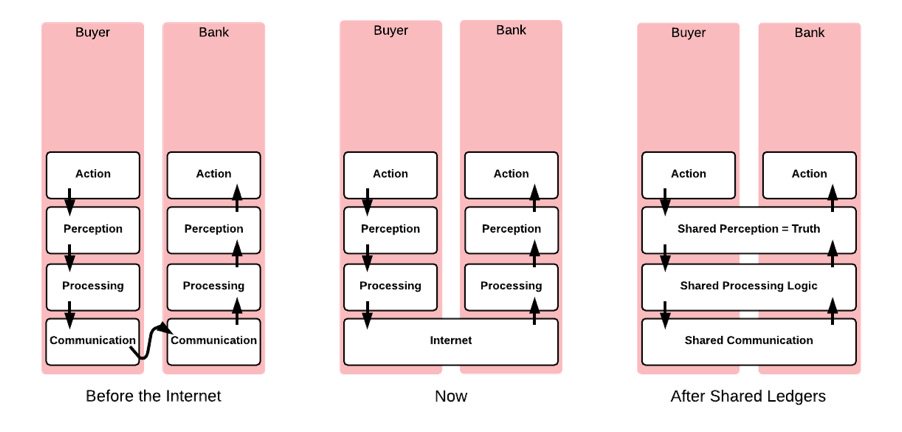
A colleague asked me an interesting question today: “how can I become a better writer?”
I’m not exactly an expert but I have opinions, and opinions are what matter these days, so I sent him an email full of ‘RGB insights’. Here is a lightly edited version of what I sent him.
I present ten tips on becoming a better writer.
Writing is thinking.
The act of writing is the act of thinking. So don’t beat yourself up if it feels painful. Thinking is hard!
You should expect to feel despair when you have a dozen half-completed paragraphs, staring out at you, none of which make sense and none of which link to each other.
Don’t worry about it… just get more of your thoughts down on paper and then start editing… move stuff around… see what happens. If two paragraphs should logically be next to each other but one doesn’t flow to the other, maybe there’s a key step in your argument missing? Are there really two different points you’re trying to make? Maybe just choose one and save the other for another piece?
The lesson I’ve learned is not to give up at this point… that chaotic process is the process. So keep going and keep reminding yourself: it’s like this for everybody (at least everybody who aspires to be good).
Writing and speaking are surprisingly similar, so practise both
Good speeches and good pieces of writing are basically the same thing: an uninterrupted, linear, coherent sequence of sentences and paragraphs, that the audience is expected to consume and understand.
In both cases, you have to know what you think, how you’re going to express it, what you want your audience to do as a result, and how best to say it, in what sequence, to get the intended effect.
I’m always brutally reminded of this in the days before I have to give an important presentation. Yes… I’ve prepared the ‘slides’ well in advance, but that’s the easy bit. The hard part is the rehearsal.
So I go into an empty room and start to present, as if live.
And it’s invariably a disaster.
Yes – I can read the bullets… who can’t? But trying to speak, uninterrupted, from beginning to end of the slideshow, cold, with no preparation, hitting the key points on each chart, setting each one up clearly, segueing seamlessly to the next page, and landing on clear concluding points the first time I do the rehearsal….?
Not a chance. Not the first time I try. Not the third.
I have to go over it again and again… really asking myself why each slide is there… why it’s at that point in the deck… what is it trying to say?
I find myself reordering slides, deleting some, realising there are some entirely missing slides, going backwards and forwards in my mind ensuring I can construct a clear narrative from beginning to end.
That, right there, is the writing process. It’s the exact same thing.
It’s the process of converting vague thoughts into precise, clear, logical and sequential sentences. There is no short-cut. So don’t stress out when it feels like everybody else finds it easy and that somehow you’re bad at it. That isn’t what’s going on at all.
“Keep it short” is the wrong advice. Write as much as you can… and then delete most of it.
How long is your ‘final’ version? How many words did you delete from your drafts in the process of getting there? The latter should exceed the former, or you ain’t done yet.
You can hide a lot of vague nonsense in wordy documents and verbose presentations. After all, if you throw enough words at the wall, some of them will make sense to some people and you’ll get away with it, or so you think. But you won’t influence anybody. Nobody will learn much.
To make a difference, it needs to be tight.
This is because when you cut it down, you have to make choices… which sentences stay? Which ones go? Again: that’s the act of thinking right there. You’re forcing yourself to decide which parts of the prose actually matter and which are just filler. Deleting is often more important than insertion.
Learn from other writers
Look at how writers you admire do it. The medium doesn’t matter… novelists, bloggers, newspaper columnists… whomever. Next time you find yourself reading something from beginning to end and really enjoying it or feeling engrossed, go look at how they did it. What tricks did they use?
Here are some I’ve stolen from others:
Start in the middle, or give the punchline first. You can fill in the blanks later. Readers will only invest in your article if they think it will be worth it. So you have to grab them quickly. Have you noticed how boring the first 30 mins ‘proper’ of each James Bond movie is as they set up all the plot? That’s why they have the exciting pre-title sequences… they know you’d walk out of the cinema if they’d forced you to sit through half an hour of exposition first. And there are lots of variations you can try here. Begin with a question to get them intrigued. Or start with an introduction that is plausible but wrong. When they realise they’ve been fooled, they’ll be intrigued and will want to stick around to find out why.
Play with style. Mix short and long sentences. Include info-boxes and quotes. Add diagrams, but be sure to give them meaningful captions and reference them from the prose.
Steal from other genres. I once wrote a paper that began as a parody of Aesop’s Fable of the scorpion and the frog. Have fun!
If you’re selling an idea, write like a (good) salesperson
At the heart of pretty much every ‘call to action’ is the SCIPAB structure. Once you know it, you can see it everywhere. If in doubt about how to structure a paper that demands action, just use this.
- What is the present SITUATION?
- Topical example: “Central Banks have a monopoly in the issuance of cash”
- What new COMPLICATION explains why we’re here?
- “Transactions are going electronic; cash will soon be irrelevant”
- What is the IMPLICATION of this?
- “Central banks could lose relevance and find it harder to discharge their responsibilities”
- What do you PROPOSE?
- “Central Banks should issue a digital currency”
- What ACTION must be taken?
- “Hire my firm to build it!”
- What BENEFITS will you gain as a result
- “You can continue to achieve your policy goals in a changing world”
Who are you writing for? If you don’t know, write for past yourself
You must have a reader in mind. Who are they? What do they know? What don’t they know? What misconceptions do they have? What biases do they have? What do you need to say, in what order, to reprogram their brain?
If you don’t know who you’re writing for, how can you possibly write something that will resonate with them or correct their misconceptions?
The good news is: if you don’t know, then write for yourself. What did you used to think about this topic that turned out to be wrong? What ‘a ha’ moment do you wish you’d had three years ago?
This also makes it easy to edit your document at the end… keep editing until you find it engaging and interesting!
Keep it simple
Lots of writers think the mark of intelligence is to use lots of long words. They act like confusing their readers means they must be super smart. The reality is that the opposite is true.
So, when you think you’re done, go back and look at your long sentences… how can you make them shorter? Are you using a complex word when a simpler one would do? Are you speaking in riddles or opaque metaphors? Remove them
Say what you mean!
Write directly, clearly and simply. And if you can’t do this, don’t beat yourself up… it’s just a sign that you need to keep going… WRITING IS THINKING… so it just means you need to keep thinking until the concepts and arguments have fully baked.
Reuse, Recycle and Plagiarise (your own work)
Writing something well is a lot of work. But once you’ve done it, you can reuse it. After all, it’s not that much extra effort to turn an email into a blog post, or a blog post into a white-paper. Indeed, “email to blog post” is exactly what I’ve done here.
So the ‘delta’ in effort to produce impactful content with longevity is often way less than you think. Think back to the last ‘important’ email you wrote where you made a case or explained something complex. Could you now use it as the basis of an internal blog post? You’ll find your thinking evolves a bit more in the process. And then you could probably also use it as the basis of an external paper. Your thinking will be even more refined.
More often than you’d expect, a well-formed, impactful white-paper is actually the third or fourth iteration of a piece of work. So the writer didn’t leap from ‘zero’ to ‘published white-paper’… there were two or three stepping stones along the way, each of them only requiring a bit of effort, and each of them having value along the way.
Nobody is born a good writer… so don’t beat yourself up.
The more you do it, the better you get. So just get writing. And remember that writing is one of the few things you can do where you incur a cost once – writing the darn thing, but obtain the benefit forever – it exists for all time and can have impact forever!
But the cliché about “today’s newspaper is tomorrow’s trash” is also true… sometimes you REALLY want what you write to be perfect. But don’t underestimate the power of ‘good enough’…. DONE BEATS PERFECT. So just write it already, hit publish and move on.
—–
Endnote: did you spot that there were only nine tips? That’s my final insight: most of the time, most people aren’t paying attention. So you can get away with way, way more than you’d expect!