Lessons from the world’s largest multi-year collaborative Blockchain research programme
If you’re not part of the blockchain bubble, you probably think people in the blockchain world are all mad! Especially those of us in the enterprise space. How on earth could we believe a technology, originally built by a group of idealistic anarchists to solve a problem no financial institution actually has, could possibly be relevant to the challenges facing those trying to build and maintain complex IT infrastructures across the world?
In this article, I explain how the work we’ve done at R3 over the last two years with hundreds of senior technologists from dozens of leading financial institutions has led me to some fundamental conclusions:
- The promise of blockchain technology is real: new business solutions will soon be deployed which can eliminate huge amounts of cost, redundancy, error and needless reconciliation across entire business ecosystems, as well as opening up previously hidden new revenue opportunities. I provide concrete examples below.
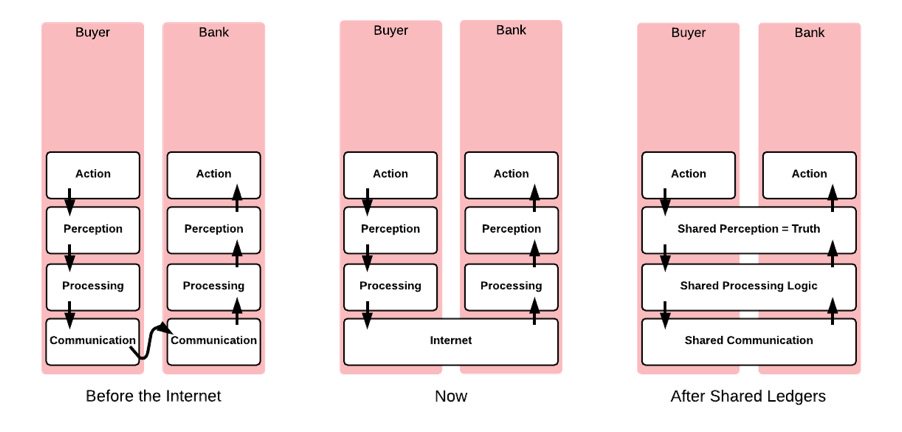
- This will be achieved by applying the fundamental blockchain insight: “I know that what I see is what you see”. This is the key to helping us move from a world of isolated, custom, inconsistent IT infrastructures in each firm, to one based on shared business logic, securely shared data, and common processes.
- The new IT architecture that is needed to capture these opportunities is one that converges the complex world of application servers, messaging engines, workflow managers and databases into a unified, secure and private design that works seamlessly within and across enterprises.
- But not all blockchain platforms are alike: Only some designs will be architecturally suited to the challenge.
- Our research has revealed several key characteristics that are needed to succeed. An enterprise blockchain platform must:
- Provide an integrated application, messaging, workflow and data management architecture.
- Build on an existing technology “mega-ecosystem” to maximise skills and code reuse.
- Eliminate unnecessary data “silos” to unlock new business opportunities by allowing real-world assets to move freely between all legitimate potential owners.
- Embed legal entity-level identification into the programming model to enable legally enforceable and secure transactions.
- Support inter-firm workflows for negotiating updates to the shared ledger to support real-world business scenarios.
- Enable the inevitable move to the public cloud without requiring high-risk technology bets.
For the last two years, I’ve been privileged to lead an intense research and development effort amongst the membership of the most vibrant consortium the financial world has seen. Hundreds of senior technologists from dozens of companies have worked with R3’s engineers to identify where blockchain technology can make a difference in large enterprises and also how it needs to be designed to achieve this potential.
This work has convinced me that the judicious application of key blockchain principles is key to rescuing the world’s banks and other large companies from the corner into which they have painted themselves after decades of investment in previous generations of technology.
In particular, we could be looking at the holy grail of enterprise software: convergence of application servers, messaging engines, workflow managers and databases in a way that works seamlessly within and across businesses.
The result is a model that delivers on the promise of blockchain in the enterprise: a world where applications can be securely developed and deployed across trading partners, enabling them to transact securely and accurately and without endless reconciliation, inconsistent data, and duplication. It is why we are now able to think about building or replacing payments systems, syndicated loans processing systems, asset issuance and custody systems, FX matching business processes and much more. And these are just examples from the banking sector being addressed by just one platform, Corda, which itself turns out to be applicable far more broadly, in areas as diverse as healthcare and identity management.
But our belief is that it is only by converging previously diverse technologies that we can dramatically simplify how companies develop, deploy and manage applications that manage their business relationships with each other.
Here’s what I mean. Through one lens, a blockchain is like an application server: it hosts business logic and ensures it runs at the right time and for the right reasons. But a blockchain is also like a messaging engine: it allows people and, importantly, their computers to exchange information and ensure that the right information gets to the right places in the right order – and to do so between companies as well as within. And some blockchain platforms also have characteristics of workflow managers; they help coordinate the activity of different parties across time and space to achieve some business outcome. And, of course, they can be akin to databases.
If we could somehow devise a platform that built on this insight and delivered a platform that could combine the function of these hitherto diverse technologies, and could do so in today’s adversarial security environment, with the necessary levels of privacy, and in a way that was easy to use and could reuse rather than replace what already exists, imagine how much simpler our future enterprise IT landscape would look!
But building a platform that combines these separate concepts is easier said than done. There’s a reason existing vendors haven’t already built something that delivers on this vision. In what follows, I’ll share the output of the last two years of our work, which confirmed to me that, by judiciously weaving together existing technologies and key advances from the blockchain world, it is indeed possible. I highlight some of the specific, key design choices you need to make in order to achieve this convergence and hence unlock the massive opportunity to transform the IT estates of existing companies.
I will refer at times to a key output from our work: the open-source Corda platform. We developed it in parallel with the research effort I describe above and, as a result, it benefited from a huge amount of expert input from across the R3 membership. No other enterprise blockchain platform has enjoyed remotely the same level of expert input. But I also refer to other enterprise blockchains where contrasts are helpful, paying particular attention to one that has come to prominence of late, Quorum, because it makes some very different choices and hence acts as a useful comparison point. This is intended to help make some of the points concrete and draw readers’ attention to areas of legitimate disagreement.
The ideal enterprise blockchain is a next-generation application server…
First and foremost, the opportunity that blockchain technology presents to enterprises is the ability to write applications that are shared between those who use them to transact. The key idea is this: rather than you and all of your trading partners each writing an expensive application to manage your participation in that trading network, you write it once. We thus share the cost and effort, whilst each running our own instance of the application in order to maintain our own books and records.
But to enable this vision, we concluded from our research that we need features that are unavailable in traditional application servers but which are common in the blockchain world. One such feature is cryptographic chains of provenance for all data in the system. When freely sharing relevant data with your trading partners, you must take nothing on trust but verify all proposed updates to the shared application state. This is also why all consensus-critical code on the platform needs to be digitally signed so you know that the code that is running is the code that should be running.
And we need to enable as much reuse of skills and existing technology as possible: you don’t save money by throwing away all the existing technology you have or by forcing all your staff to retrain! So you should be able to write applications in languages that have as large a population of developers as possible. Working with our diverse membership, we concluded that Java is by far the most widely deployed language across the business world and so we focused on that ecosystem. There are almost ten million people in the world who have these skills. But we also found that large enterprises hunger to bring their infrastructures right up to the contemporary cutting edge, so support for techniques such as reactive programming, approaches like functional programming and new languages like Kotlin and others are also required.
In short, the ideal application server for the modern era is one built for security, productivity, data integrity and cost minimisation.
But don’t all enterprise blockchains do this? Actually, no. To see that, we can compare the approach we took with Corda – the result of our two year journey – with a competing blockchain platform such as Quorum. Although superficially similar to Corda in the way it describes itself it is, in fact, a relatively small fork of an existing public blockchain platform called Ethereum – which was designed to solve a completely different set of problems. Quorum inherits all of the associated advantages and disadvantages as a result.
For example, rather than supporting a full range of modern and mature languages to suit different needs, for which there are abundant skills and existing libraries, as Corda does through its support for the Java Virtual Machine, Quorum only supports languages that run on something called the Ethereum Virtual Machine. The EVM is a young, purpose-built virtual machine maintained by a community primarily focused on executing cryptocurrencytransactions and associated business logic. No mainstream languages run on the Ethereum virtual machine. This raises obvious questions around skills and integration with heritage systems. But it also opens up serious new risks for those who try to apply Quorum to real-world business problems. For example, the most popular language for writing applications on Quorum has been repeatedly shown to be impossible to use safely, suffering from countless bizarre language features that have led to people losing real money.
Not all enterprise blockchains are alike.
The ideal enterprise blockchain is also a next-generation messaging platform…
However, as I argued above, the exciting realisation during our research effort with our member banks was that good blockchain platforms are also inspiration for how to rethink enterprise messaging systems. Messaging systems are used by big companies to link computers and applications to each other securely and reliably.
The need for this becomes acute when you talk about deploying shared applications betweentrading partners. The applications running on different firms’ nodes need to be able to communicate. We need all parties to be securely identifiable and to be able to communicate with each other near-instantly over the internet or private network, addressing each other by legal name. It’s not good enough to take existing enterprise messaging platforms that let you communicate with an address or a queue; you need to be able to talk to a named legal entity, anywhere in the world.
In our work with the diverse group of technologists from across our membership, we identified that the way to achieve this was to take existing technologies – in this case, TLS, X.500 and more, and make them consumable and accessible to today’s application developers. It seems obvious when you think about it yet no mainstream platform offered it in this way until we supported it in Corda. It was necessary to weave insights from the cryptography community, where public key infrastructure is well understood, and the banking community, where financial networks between identifiable peers are common, to come up with the idea of “send to legal entity” as the natural and obvious way to communicate between parties.
A separate finding from our work was that large institutions are institutionally allergic to anything that looked like it could create new islands of connectivity. They needed a platform that would allow multiple independent Business Networks to operate within a single global namespace – perhaps something we could call a Compatibility Zone. No more tolerance for isolated silos of communication and data distribution (unless you want it of course…). And this turned out to be key for the delivery of the holy grail: true representation of real-world assets on a shared network, with no artificial barriers to exchange or transfer, which I talk about more below.
Achieving this level of seamless interoperability across multiple business networks, whilst retaining flat, transparent, legal-entity-level addressing is hard. But I think we’ve achieved it with Corda. And it’s something that is lacking in platforms like Quorum, where network membership is defined in text files which must be copied to each node, and where behaviour is undefined (or, rather, may have “adverse effects”) if they don’t match perfectly.
Identity and legal-entity addressing can’t be an after-thought in a text-file: they need to be designed in from the start.
The ideal enterprise blockchain is also a next-generation workflow manager…
When I worked with clients in my previous jobs, I would find they deployed workflow management tools, also sometimes called “Business Process Management” platforms, inside the organisation to control and optimise the flow of work between people and systems.
But all too often these systems would stop at the edge of the firm. The “other side” was treated as a black box. And yet, it is in the interaction between firms that the risk and cost creeps in. Did they receive the message? Are they working on it? Did they understand it and process it correctly?
Do they see what I see?
This isn’t actually something that existing blockchain platforms provide much help for. And yet it is a real need even for some simple cryptocurrency transactions such as implementing an escrow arrangement or telling somebody how to pay you! In essence, for every meaningful transaction on a blockchain platform, there is usually an out-of-band negotiation flow that needs to take place. Just like in real business.
And as we worked through countless use-cases during our research, what emerged was a need to make it easy for developers to write this back-and-forth business logic for the collaborative negotiation of a deal or construction of a transaction.
We discovered a need for an inter-firm workflow automation technology where developers don’t have to worry about any of the complex technical work necessary to orchestrate such co-operation at scale across a global network. In particular, it needs to be possible to define business processes that flow between, within and across firms, yet which can be coded in a simple and natural programming style, where you can express what each party in a transaction should do and have that work automated within and across your firms.
Unfortunately, developing something so ambitious would be hard if implemented from scratch. So it provided further weight to our emerging belief back then, a certainty today, that a successful blockchain platform for the enterprise has to build on the work of an existing, massive ecosystem, where it can reuse as much existing infrastructure and code as possible.
If we now turn to the specific case of Corda, we were able to take cutting edge technologies from the Java ecosystem and add some seriously clever engineering by the R3 engineering team to deliver something unique called the Flow Framework. In particular, recent advances in automatic checkpointing of business logic, with restore across system restarts, means developers can write what looks like entirely normal straight-line logic and yet, behind the scenes, a complex international workflow is being orchestrated. The first time you use it, it feels a bit like magic. This is an example of why it’s so important to build on the foundations of an existing and robust ecosystem, such as that provided by Java, whilst at the same time bringing the programming model and tools right up to the contemporary cutting edge.
The ideal enterprise blockchain is also a next-generation asset ledger…
A repeated theme from our work with members was that the real wins come when the new enterprise blockchain applications become systems of record for real transactions.
This means they need to provide legal certainty. Application developers need to link their contract code to associated contract legal prose to give certainty about how disputes will be managed. But, for this to work, one must go further. Just as a successful enterprise blockchain identity layer needs to be based on legal names, the actual nodes – the machines running the business logic – also need to be clearly associated with a specific legal entity.
Such a framework, provided by the legal prose, identity-driven messaging and legal entity association with nodes, means that contracts signed on platforms that support it can be legally binding if you choose. It’s a prerequisite to being safely able, at scale, to support direct issuance of assets and the direct formation of contracts.
It means that a bank or other firm can issue assets (cash, equities, even commercial paper or syndicated loans) on to the ledger and have them be directly owned and seamlessly transferred to other members of an appropriate business network in near-real-time and with settlement finality.
And make no mistake: that is a hard trick to pull off. For dematerialised assets to have full utility, they must be easily transferrable to any and all legitimate potential owners: isolated islands won’t do. So it turns out that this also has strong implications for the most fundamental aspects of the design: how data on the blockchain is managed, distributed and evolved, which I describe more below.
The issue we found during our research was that if you get this wrong, you risk trapping assets in silos, where they can only be transferred amongst members of a preconfigured list or through the involvement of third-party market-makers, or by asking the issuer to impose friction by cancelling and reissuing them.
It’s a tough problem to crack, as the link above makes clear in its analysis of another platform. The criticism in that link also applies to Quorum: they both suffer from this stranded asset problem and it means apps you write for those platforms will almost certainly have to be extensively rewritten in the future when those platforms are redesigned to correct these shortcomings. A costly prospect.
It’s one of the reasons we were so focused on delivering a version of Corda with “API Stability”: members and other developers told us loudly and clearly that they highly valued knowing they wouldn’t have to redesign their apps in the future
And the ideal enterprise blockchain is also first-of-a-kind decentralised database…
At the heart of the enterprise blockchain vision is the idea that, if two or more parties are transacting with each other, then they should all have an identical copy of the associated data.
“I know that what I see is what you see”.
To achieve this, we have to ensure that all parties have fully validated that their shared state was indeed calculated correctly. At heart, it is this that distinguishes blockchains from what went before: we don’t take things on trust; we verify. And to verify we need to run the logic for ourselves. We have to check the provenance of data.
What we want is, in effect, a globally shared database, but where each party only has the rows of the database that pertain to transactions they’re part of. So we need to make sure that you receive the rows you need and if anybody tries to change any of them, they can only do so if the rules are followed and that you get to sign off on it and/or get notified afterwards as appropriate. To get an idea of how this works under one architecture, see this simple analogy.
The design we concluded that best achieves this is one that builds on and heavily extends and generalises ideas that originated in Bitcoin rather than Ethereum. This model, which Corda adopts, encourages developers to think of the fundamental units of information in their business problem and how they can evolve over time in isolation. Corda then adds the powerful flows I described earlier to orchestrate their updates via transactions that specify precisely which data units – “state objects” – are being referenced, created or replaced.
This approach allows for arbitrarily rich scenarios and sophisticated negotiations and business processes to be modelled with ease, whilst allowing the system to tell precisely who needs to receive what data, when, whilst revealing nothing more than is needed to prove provenance.
Other platforms take a different approach, based on an Ethereum-like model. They typically start with the idea of an “everybody sees everything” full broadcast blockchain, representing a globally shared computer, and go fractal in order to correct for the privacy issues that result: they spin up tens or hundreds or thousands of separate mini shared-computers, one for each group that wants to transact in privacy. This approach can work but our analysis, confirmed by later experience, was that, for real world scenarios, it gets very complex, very quickly.
In the case of Quorum, each “confidential contract” can be thought of as a mini Ethereum universe that is visible only to the participants in that contract. This idea of millions of mini-blockchains works for some scenarios, but as I described in this post the approach, used by some other platforms too, fails completely if you ever need to support asset mobility. As soon as you need to prove provenance of one piece of data in a confidential contract to somebody else, you have to show them everything in that contract. Game over: you either lose privacy in the hunt for provenance or your assets are stranded, with their provenance impossible to be demonstrated to outsiders.
And… the ideal enterprise blockchain must also be designed for the cloud
The world doesn’t stand still. The enterprise software market in 2017 is different to the market in 2000… In particular, most new applications that get deployed in the future will run in the cloud, increasingly in a public cloud.
So this was inevitably a hot topic of debate throughout the consortium’s deliberations over the last couple of years: how can we support application developers who need to write applications that will form legally binding contracts and be the basis of their audited books and records yet which will run on other people’s computers in a potentially hostile environment?
We considered the obvious options: zero-knowledge proofs, homomorphic encryption, secure hardware and more, and combinations of them all.
Our first conclusion was that the answer needs to be multi-layered: deterministic sandboxes, signing of all code and transactions, everything underpinned by legal-entity-level addressing, support only for a well-understood and tested managed runtime (in Corda’s case, the JVM, which we heavily lock down) and so forth.
But we also made a decisive choice: when weighing up risk, availability of skills, time to market and a collection of other factor, we concluded that the right initial approach is first to support hardware security technologies and, Intel’s SGX technology in particular.
This allows users to deploy Corda applications to other people’s computers (ie on public clouds) in a way that prevents those operators from interfering in transaction verification or accessing historical transaction information yet with no material limitation on the business logic that can be run. And we found that making this work well required it to be designed in from the ground up, which we did.
We concluded that this approach contrasted favourably with a higher-risk one being taken by platforms such as Quorum, who are recommending today the use of zero-knowledge proofs. Zero-knowledge proofs are a very fine piece of engineering and mathematics. They’re almost certainly part of the future of privacy in the long-term on blockchains – and Corda is designed to adopt them when they have matured. But, today, the story is different.
First, and as Mike and Kostas in our engineering team discussed at CordaCon in September, the world of Zero Knowledge Proofs is young, very few people have skills, it is almost impossible to know what one of these things actually does when written and the security assumptions they rely on are unproven. Indeed, the “zk-SNARK” technology being promoted in February this year by the inventor of Ethereum is now being challenged by something new, called zk-STARKs. This is a promising sign of a vital research community, rapidly advancing a young field. But it’s a risky foundation upon which to build enterprise solutions before it has matured more.
Secondly, the integrity of the financial system rests on the idea of atomicity: related activities should either all happen or not happen at all. Inconsistent, half-complete exchanges just won’t do.
This requirement was hammered home to us by our members during the design process for Corda and so the ability to do complex atomic “payment versus payment” and “delivery versus payment” transactions is a fundamental part of the architecture.
Unfortunately, Quorum, which needs to use zero-knowledge proofs to achieve acceptable privacy in their system cannot, according to their own documentation, achieve delivery-versus-payment:
“… the POC solution will not support cryptographically-assured DvP (i.e. atomic exchange of assets). This is because ZSL currently has no means of supporting shielded DvP-style functionality.”
This is why it’s so important to distinguish between the generic promise of enterprise blockchain technology and the practical reality of specific implementations.
Thirdly, we need to remember at all times that this whole emerging industry is about consensus, about being sure your counterparts really do see the same things you do and that you agree on all important data, when it happened and in what order.
But we learned from our members that how you reach this consensus may need to differ based on the business context: maybe you’re trading amongst a group of peers who you know well: you may each need to participate in the decentralised consensus forming process by running a node as part of a consensus cluster and reach consensus quickly and with finality amongst yourselves. But, perhaps for some other line of business, you’re transacting with people all over the world and you want an independent, decentralised group of impartial observers to timestamp the transactions and help you reach agreement about ordering. That must also be supported: you need to be able to use a fully byzantine-fault tolerance decentralised cluster of consensus nodes, operated by mutually distrusting entities. And a successful platform needs to support all these modes – and more – and, here’s the key part: on the same network, at the same time!
So when we designed Corda, we engineered it so that you’re not forced to pick one consensus model and expect everybody to accept a one-size-fits-all for every transaction they perform on their blockchain network. That would be the road to disconnected, isolated blockchain networks… and the fast lane to stranded assets.
Why I believe Corda is the future of enterprise software
This piece began by outlining what I consider to be some of the critical findings of our journey so far. And we’ve embedded as many of them as possible into the design of the platform we jointly defined with this unprecedented consortium of institutions and the hundreds of technologists who so willingly gave their time to help us get it right.
It’s why I am so careful to stress that all enterprise blockchain platforms are not the same.
There is a reason Corda looks different to platforms like Fabric and Ethereum. It’s because we’re not merely trying to take public blockchain technology – designed for a completely different purpose – and force it inappropriately into the enterprise.
Instead, we’re doing something altogether more exciting and ambitious: we’re building the future of enterprise software. We’re tapping into one of the largest technology ecosystems ever seen, the Java ecosystem, and building on the work of countless thousands of skilled engineers to deliver an enterprise blockchain that’s designed directly to solve real problems faced by businesses today.
It’s why I believe the Corda enterprise blockchain is the future of enterprise software.
Indeed, firms like Finastra, Calypso, HPE and others discovered Corda for themselves after reaching similar conclusions as us about what the right design for a consensus system between identifiable parties in a regulated environment needs to look like and our large and growing roster of partners, including Microsoft and Intel, is a testament to the momentum.
Perhaps I shouldn’t be surprised: we were immensely fortunate to have the deep and insightful input of literally hundreds of senior technologists from across dozens of the world’s largest companies help with the design. I hope one day to be able to list each and every one of them.
Indeed, I hope we will look back on Corda in a few decades as one of the largest and most successful collaborative design efforts in the history of enterprise technology!
Finally: a note on terminology. In this post I used the word ‘blockchain’ to describe Corda. I tried for a long time to retain engineering purity (“Corda is very much like a blockchain and has chains of transactions but, strictly speaking, it doesn’t batch them into blocks – it’s real-time – so we probably shouldn’t call it a blockchain!”) But the reality is that the market uses the term Blockchain to describe all distributed ledger technologies, including ours. So I’m not going to fight it any more…!