They key to understanding mining is to realize we need blocks to be produced slowly!
Whenever I present Bitcoin to new audiences, I avoid talking about mining. I find it confuse more than it enlightens. Instead, I simply give some intuition. I say:
“Today’s value-transfer systems rely on central ledgers. Banks, telcos and other firms have a big computer that keeps track of who owns what. And when you want to make a payment, they update this central ledger. Bitcoin does it a completely different way. It doesn’t have a central ledger. Instead, everybody who runs the (full) software has their own copy of the ledger. That’s right: hundreds of thousands of people all have a full copy of the ledger. This means no single person can cut you off, confiscate your assets or charge you an unfair fee. And the genius of Bitcoin was to figure out a way to encourage people to maintain these ledgers and to do so honestly. Exactly how this works takes a long time to explain but the end-result is that we have a system with no trusted third parties.”
The value of this explanation is that skeptics in the audience know what assumptions I am asking them to make (“assume for now that the economic incentives and cryptography do actually work…”) but we avoid getting bogged down in unnecessary technical detail. It lets us move on to the more interesting topics
OK – so we have a way to side-step the mining question. But what if you actually need to talk about it? What then?
I am enlisted on the University of Nicosia’s Digital Currency MOOC, led by Antonis Polemitis and Andreas M. Antonopoulos and I was intrigued to see that they attack this question and the “byzantine generals” problem head-on in module two. It’s a very nice treatment.
In this post, I take a complementary approach and ask: how would I build a digital cash system from scratch if I didn’t know anything about Bitcoin? What might I try first? What might go wrong? How might I fix it?
Let’s go on a journey to build our own digital money system from scratch…
Imagine you wanted to build a system of electronic cash without a third-party. How would you do it?
Here’s one way. You could create some “money files” on your computer hard drive. These would be like bank notes. Maybe they’d look something like this:

An early attempt at a digital money system!
In the picture above, I have two “ten pound” files and two “five pound” files. Great – I have £30 of digital money. This is easy… Why did it take so long for Bitcoin to be invented?!
Now… let’s say I wanted to send £10 to a friend. This would also be easy. I’d just need to write an email, attach one of the “ten pound” money files and click “send”. Wonderful! The money has been transferred.
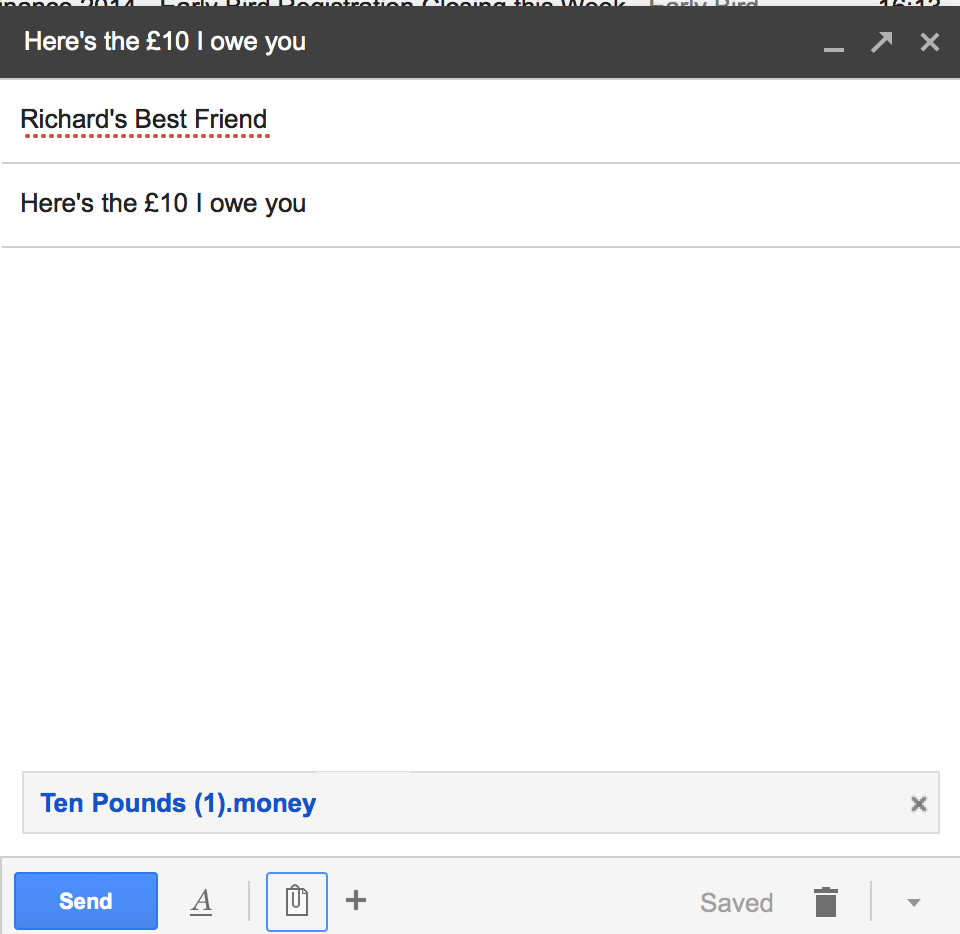
Emailing £10 to a friend. Who needs Bitcoin?
There’s just one problem…
There’s still a copy of that file on my computer. So there was £30 in the system before and now there is £40. Now… I am, of course, honest and will delete my copy. But what if I forgot?
Worse, what’s to stop me simply making hundreds of copies of the “ten pound” file on my computer? I’d be RICH!!
This idea simply isn’t going to work and that’s why digital money systems have the idea of a ledger: there needs to be something that everybody trusts to keep proper track of how much money each person has. We need this ledger to record the fact that I have £10 less and my friend has £10 more.
All systems before Bitcoin did this using a centralized ledger – in a bank or a telecoms firm, say.
But does this ledger really need to be centralized?
But here’s a thought what if I sent the “money file” attachment to my friend – just like before – but I also put everybody else in the entire world on cc?
The rest of the world could see that I had sent the money to my friend and if I tried to send the same file again in the future, they’d see that I was cheating and I’d be in big trouble…
If we leave aside questions of scalability, we could be on to something here…
But… race conditions are our enemy
But there’s an annoying problem. Software engineers call it a “race condition”. It’s still possible for me to cheat, even if the whole world is watching.
Here’s what I could do:
Imagine I owed £10 to each of Alice and Bob and wanted to cheat the system by sending the same £10 money file to them both:
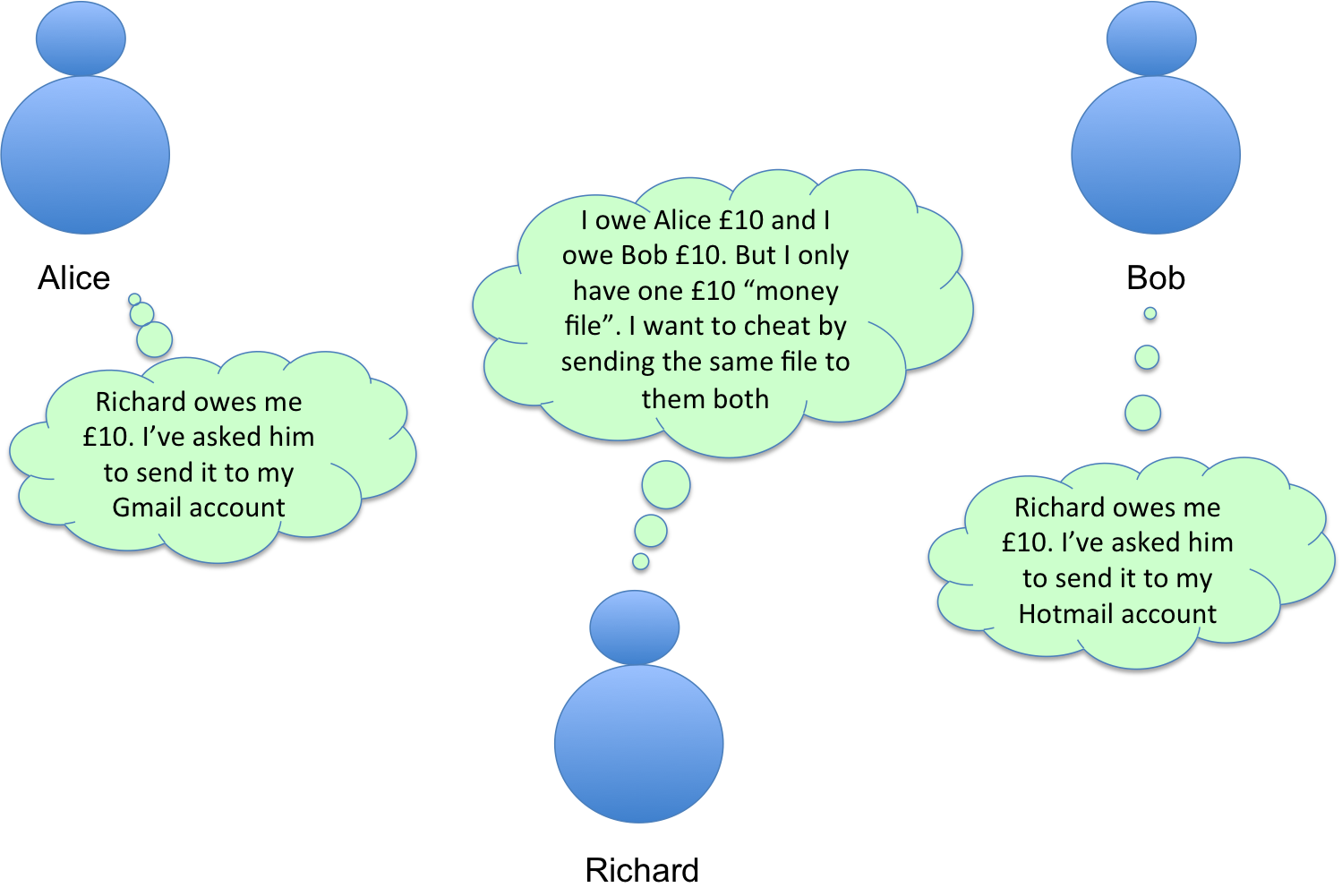
I owe £10 to two people and want to cheat by sending them both the same £10 “money file”
I notice something interesting… Alice and Bob use different email providers…. And I know that information takes time to travel.
What would happen if I use my Gmail account to send Alice’s money to her Gmail account and I use my Hotmail account to send Bob’s money to his Hotmail account, copying everybody in the world on both emails per the rules?
Different people will see the emails arrive in a different order depending on which email provider they use.
Imagine you’re another user of Gmail:
You’ll receive a copy of my email to Alice pretty quickly. After all, I sent it from my Gmail account. Shortly afterwards, you’ll receive a copy of the email I sent to Bob. It arrives a bit slower because it’s coming across the internet from my Hotmail account.
Now imagine you’re another user of Hotmail.
You’ll receive a copy of my email to Bob pretty quickly. After all, I sent it from my Hotmail account. Shortly afterwards, you’ll receive a copy of the email I sent to Alice. It arrives a bit slower because it’s coming across the internet from my Gmail account.
And now imagine you use a completely different email service. Who knows which email you’ll receive first… it will be effectively random.
So we have a big problem: everybody will see that I’ve tried to spend the same money twice…. that’s something, I guess. But they won’t agree whether Alice or Bob is the rightful recipient! Some will think I sent it to Alice first – and that the payment to Bob is therefore invalid – and some will think I sent it to Bob first and that the payment to Alice is invalid!
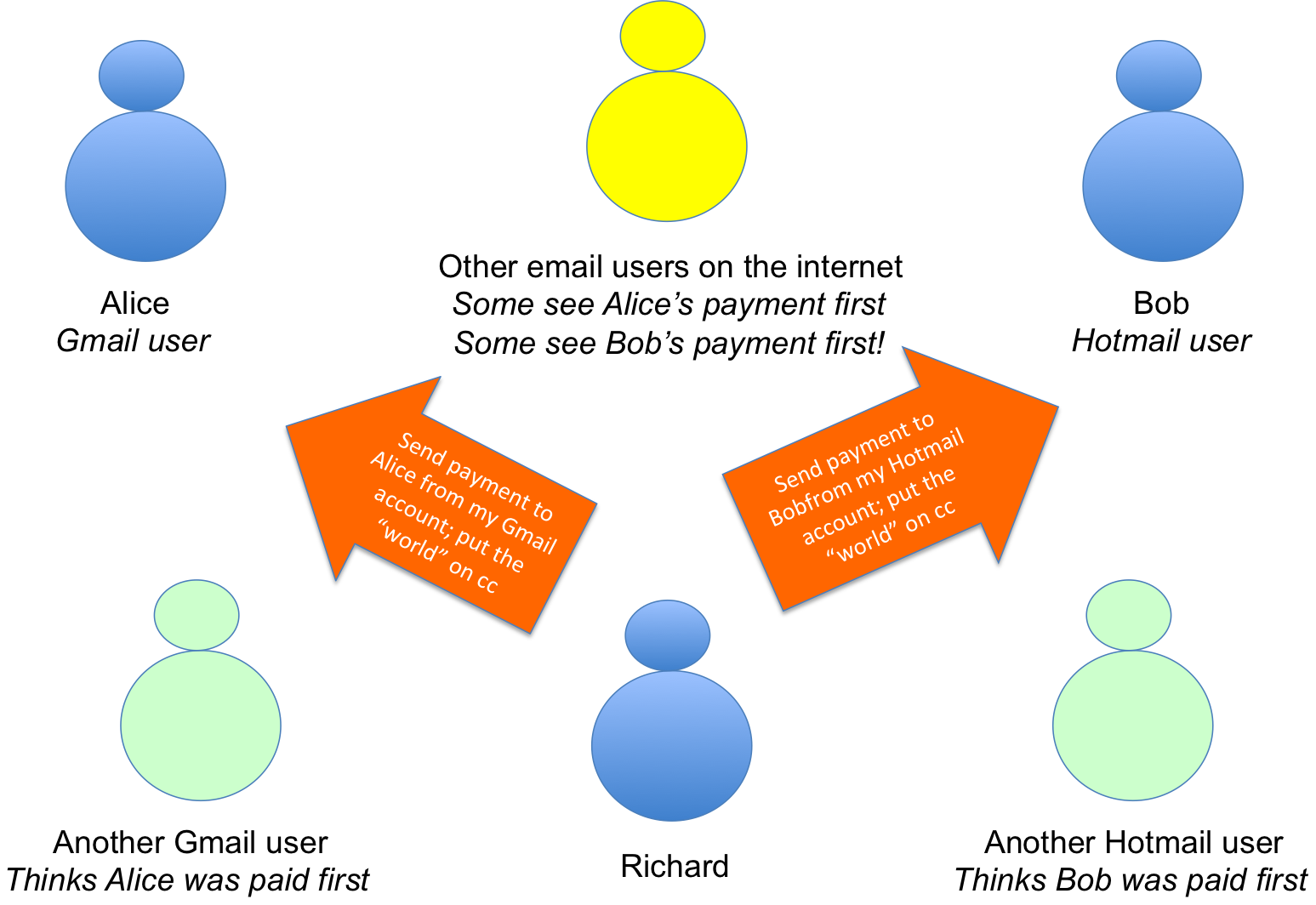
There’s no such thing as total “ordering” in a decentralized system
And there’s no easy way to resolve this… we can’t rely on timestamps since I could fake them(and they might be identical). And we can’t simply say: “if you see a double spend then neither transaction is valid” since it would mean I could always block up the system and “take back” money simply by issuing a new payment to confuse everybody…
Oh dear.
But notice something interesting: it doesn’t matter whether Alice or Bob is judged to be the rightful owner, since one of them was always going to be disappointed. We just want everybody to know who it is.
And this is the insight that allows us to begin to solve the problem.
Because it means we should think of these payment emails to Alice and Bob not as definitive payments but as payments proposals. They might be valid. Or they might not. We need the “system” as a whole to determine it – it needs to come to consensus.
Now… figuring this out on a payment-by-payment basis would be overwhelming. So we’ll settle for a system that batches up these payments proposals into lists – or “blocks” – of confirmed payments.
So where have we got to? We have this idea of directly sending “money files” to recipients – “peer-to-peer”, if you like. And we have the second idea that you also tell everybody else in the world about it so they can see what’s happening. And the key problem to solve is: how do we come to agreement when payment proposals conflict?
Let’s bring the observers into the picture
Here’s something we could do: we could say to all the people on cc:
“hey… help us out here. You’ve been copied on all these payment proposal emails. Why don’t one of you choose a selection of payment proposals that haven’t already been confirmed in the past and which don’t conflict with each other and email the list to everybody else? We’ll all agree that the list you circulate is the one we’ll go with to resolve the conflicts”
If we’re lucky, somebody might look through their inbox, choose some unconfirmed payment proposals and draw up such a list. Perhaps they decide that they will include the payment to Bob in their list. This means they can’t also include the payment to Alice (since those payments conflict with each other – they use the same underlying payment file). But at least we have a decision! They email this list to everybody else in the world.
Everybody receives a copy of the list and can update their own view of the world… their copy of the “ledger”, if you like…
So we all now know that a decision has been made: We have agreed through this “protocol” that Richard has paid Bob and the payment to Alice is invalid. And we know this because we know everybody else received the same file and will be following the same thought process.
Excellent. We now know Bob has the money and the world moves on. We’ve solved the problem right?
- We have this idea of “payment files”
- You “spend” them by emailing them to the recipient and copying everybody else in the world.
- Somebody on copy periodically produces a list of transactions they’ve seen that are not fraudulent and are not “double-spends” and circulates this list to everybody else.
- Everybody who receives this list knows that everybody else has also received this list and that everybody else knows that they have received it and so feels confident in updating their own records to record that the payments in this list are now “confirmed”
Except… why on earth would anybody go to the trouble of producing and circulating that list in the first place? What’s their incentive?
There really isn’t one. So we need to incent them. Perhaps they can earn a small transaction fee or perhaps we could award them some newly created “payment files” in return for their effort. That would be a neat way of introducing these payment files into the system in the first place, in fact.
But now we have the opposite problem… everybody will want to produce these blocks and we’ll be overwhelmed with competing blocks being emailed to everybody… it will be like the worst “reply to all” email tsunami ever and nobody will know which of the competing blocks to use to update their ledgers!
It feels like we’re back to square one.
The world’s first technology platform that works because it goes SLOW
Except… and this is the genius of Bitcoin. What if we could agree on a system that makes it so difficult to produce one of these lists that, even if everybody is trying really hard, they only produce one every few minutes?
The would give enough time for the list to work its way around the internet. And once you received it, you could be pretty sure there wasn’t a different one flying around because they are only produced every few minutes and if there was another one, you’d have seen it by now in any case…
So now you have the right balance: incentives to ensure somebody produces these lists (Bitcoin calls them “blocks”) and a system that makes it difficult so that they’re not produced so quickly that we end up with multiple competing blocks at any time.
And this is what Bitcoin mining is all about. It’s nothing more than participants in the system competing with each other to find one of these valid blocks in order to earn the reward.
Bitcoin aims for a “block interval” of about ten minutes. Perhaps this is too slow. Perhaps it’s too quick. But it does achieve the aim of ensuing the blocks usually have time to reach everybody else before the next one is found.
Now… the system in use by Bitcoin is probabilistic… so sometimes two blocks are produced in quick succession. But this is rare… and you can deal with it when it only happens occasionally.
So how do you make things go “slow”?
One way to make block production slow is to make it incredibly difficult to produce one. This is what Bitcoin does. It uses a system called “proof of work”, where participants essentially have to perform nearly identical calculations again and again and again until a solution matching a pre-agreed pattern is discovered… and the difficulty of this problem is periodically adjusted so that a solution is found every ten minutes on average.
This seems wasteful but we need something just like this to achieve our aim of not producing blocks too quickly.
But there are other options. For example, one variant of a scheme called “proof of stake” makes it difficult to find a block unless you own several coins and you haven’t done anything with them for some time. This combination of “stake” and “time” dramatically reduces the opportunity for participants to find blocks and so the rate is kept low, without computers having to burn electricity solving puzzles to the same extent.
The security analysis and design of such schemes is an active area of research.
Conclusion
I have omitted some (lots of) important details and it’s clear that the “payment file” analogy is highly imperfect. But I think encouraging people to consider “how would I do it” can help impact a considerable degree of understanding. And the key insight is: “Cryptocurrency systems work because they are the first computing platforms deliberately designed to go slow!”

A delightfully elegant explanation.
Though you will then have to cope with the annoyingly clever student who asks “What is to stop a bad person from solving a block that he has compiled out of fake transactions, thereby rewriting history?”
😉
Hi David – thanks for the feedback. Good point about the potential attacks…. I considered introducing the need for the blocks to be chained — and you’ll notice that I didn’t say anything about signing the transactions — so yes… LOTS of holes in the story!!
A truly wonderful and clear explanation of bitcoin and mining, a rarity, …awesome job!
thanks for the great article, richard; probably the most approachable and bottoms-up explanation of bitcoin/blockchain that i’ve seen!
This blog dives into Bitcoin mining, highlighting the intriguing concept of it working because it goes slow. It’s like a fresh perspective on the tech race. The idea that the deliberate pace of mining somehow adds to its effectiveness is mind-boggling yet fascinating. The blog is a quick and thought-provoking read for anyone curious about the dynamics of Bitcoin and the tech behind it.