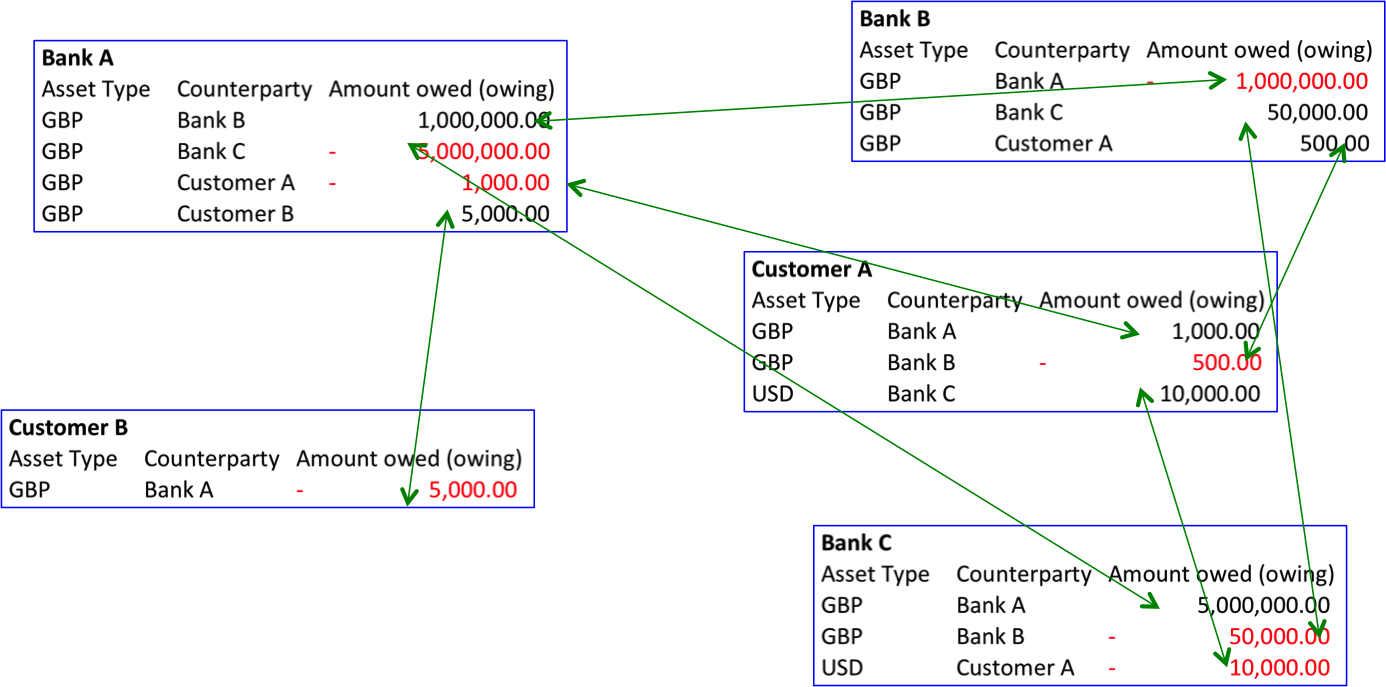
“Channels” in Hyperledger Fabric don’t work the way you think they do…
Corda and Fabric have very different approaches to delivering privacy. In this post, I compare the models, explain why Corda works the way it does and why I think the Fabric privacy model is flawed. It turns out this can have real-world costly business implications.
But first… let’s set up some intuition.
If you’ve ever used the popular messaging tool, Slack, you might recognise this message…
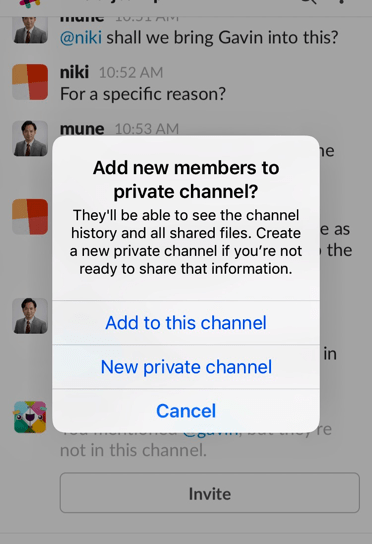
If you add a new member to a private channel in Slack, you have two choices: share your entire history or start a fresh, empty, channel. This works for interpersonal comms but it turns out it doesn’t work nearly as well for the “trust but verify” world of enterprise blockchains.
This message reveals a fundamental truth: if you’ve shared lots of information in private with some people – on Slack or in an email thread, perhaps – then you have to be very careful about adding somebody new to that group, especially if you care about controlling what they can and can’t see. Remember that time you added somebody to a long “reply-to” chain, only to realise there was something at the bottom that you really didn’t want them to see?! Undo! Undo!! Undo!!!
Famously, there’s no “undo” button on a blockchain, so we have to get things right first time.
In this piece I’ll explain how Fabric’s privacy design turns out to be very similar to Slack channels. However, it also turns out that a model that works superbly for Slack doesn’t work as well in the world of enterprise blockchains for some very common use-cases.
But first, some history.
When we began our architectural journey at R3, we examined a large number of platforms. We concluded that none met our needs and we embarked on the project that culminated in Corda, the industry’s only finance-grade enterprise blockchain platform.
One of the platforms we included in that initial evaluation and rejected as unsuitable for the broad range of needs of sophisticated financial institutions was the first version of the Fabric platform.
But that was then… and a lot of time has passed. It’s always valuable to revisit past decisions in the light of new evidence and, since Fabric has just reached an important milestone, now is a good time to look again.
One of the key changes since 2015 is the introduction of something called “channels”, intended to address the severe privacy shortcomings in the initial design. It turns out that Fabric channels are very similar to an idea we had considered and rejected as too limiting at the start of the design process for Corda.
In this post, I explain why we rejected this design for Corda and what I think some of the key problems will prove to be.
As we know, early blockchain designs sprayed data around the network and everybody received and processed every transaction. This is how Bitcoin and Ethereum work and it is, of course, a fundamental part of how they work. It’s the right design for those public blockchain platforms.
But that design, which is perfect for those platforms, is just not appropriate for most problems in today’s enterprise world. So the first version of Fabric, which broadcast data globally like many other platforms of the time, had to be extensively redesigned.
The new solution adopted by Fabric is called “channels”. The idea is effectively to let you set up many, many “mini blockchains” – each of which is called a “channel”. So you and I may share a channel. Perhaps Alice, Bob and Charley share another one. And maybe Alice, me and Ivor share another one. It’s as if there are many little private blockchains where members of a channel can see everything in that channel but nobody else can.
Simple, right? Elegant, right?
Unfortunately, no.
My biggest worry about the design when we first considered – and rejected – it for Corda is that assets will get stranded.
Imagine you issue a bond to an investor in a private channel between you and them. Remember: the whole point is that it’s private so you wouldn’t want anybody else in that channel. Why would you want them to know about your private deal?
And now you have that channel with your investor, you can use it to engage in some other transactions with them too. Perhaps you use this bilateral channel to manage some records pertaining to some other deal you’re working on together. Or maybe they’re also a customer of yours and you want to manage a complex order. There will invariably be lots of different pieces of information in a channel – different deals, trades, records – all being managed together and commingled. And this will be repeated across all the other bilateral and multilateral channels in which you participate.
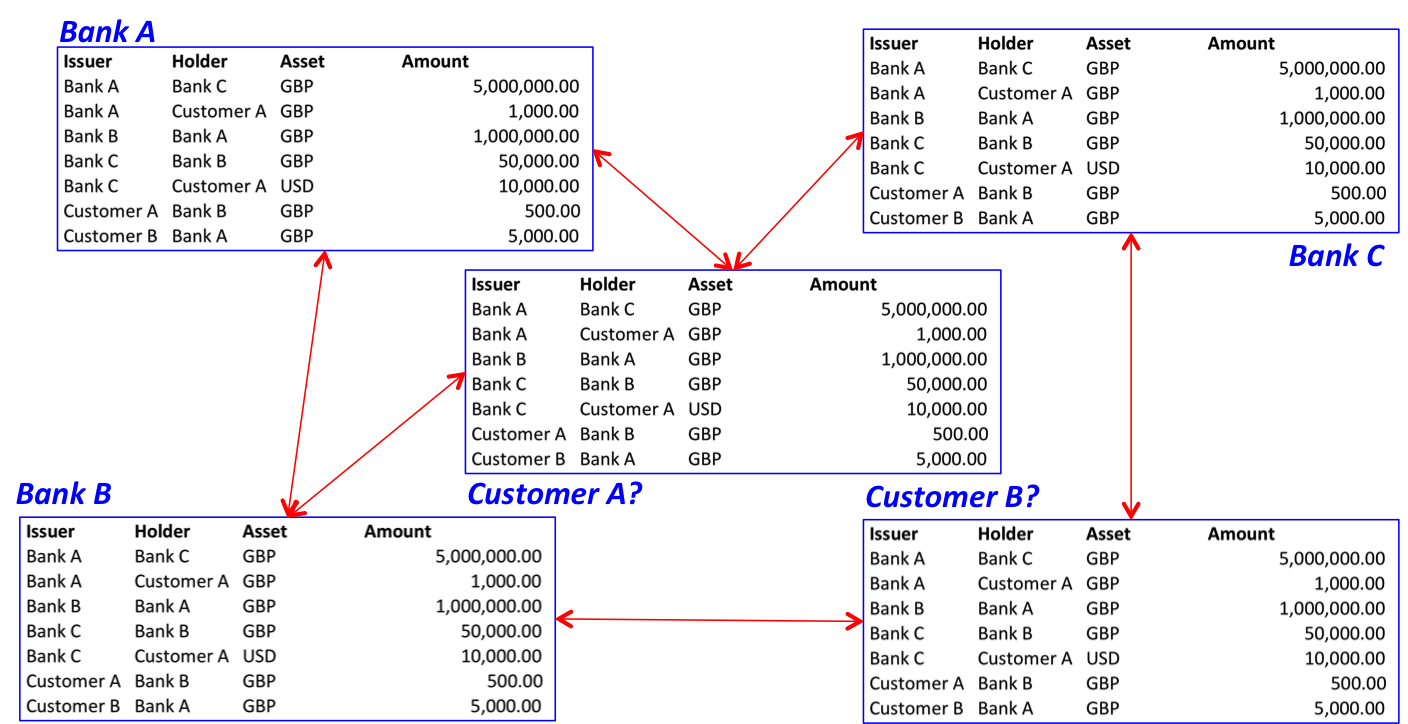
And, because of the nature of the programming and consensus model used by Fabric-style blockchains, all information in a channel inevitably gets commingled with all other information in that channel. There’s no easy way to extract just some pieces, with history and provenance… a channel is an all or nothing proposition. This is intrinsic to how these sorts of blockchains work and is a reason Corda uses a totally different architecture based on individual “states” representing specific shared facts, each of which can evolve independently.
A good way to think about this problem is as if a channel is like a break-out room at a conference… filled with whiteboards and sticky-notes on the wall. If you’re in the room, you can see and understand everything… but if you were to just take one piece of paper out of the room, it would make no sense to anybody else because they’d need the full history of everything that happened in the room and all the other papers to understand it.
Or, rather, I thought that was a good way to think about it until I sent an earlier draft of this article to some colleagues for review and one of them pointed out that this is precisely what happens when you manage private conversations in Slack!
If you set up a private channel in Slack and then try to add somebody else, they get to see everything that went before. Or… you have to set up a brand new channel where they get no history, no context, no provenance. It turns out the Slack app even has a perfect error message that describes this issue:
Slack knows why a channel architecture is problematic for a distributed ledger
So imagine you want to take a bond you’ve bought from the issuer in that channel and sell it to somebody else. How would you do it?
- Well…. you can’t invite them into the channel, because then they’d see all your other private information. A non-starter. It would be like inviting them into your secret breakout room and hoping they didn’t look at things they weren’t supposed to.
- And you can’t easily just extract the pieces of history needed to prove the history of that bond, because everything is commingled.
- And you can’t simply tell them you own the bond. Why would they believe you? The whole point of enterprise blockchains is that each party verifies the information it is given. This is what distinguishes enterprise blockchains from databases, after all.
- I suppose you could ask the issuer to cancel the issuance in your channel and reissue it in the new buyer’s channel. But now we’re getting a little bit silly. This would be indistinguishable from simply managing the assets on the books of the issuer. It would defeat the point.
This is not just theoretical: it could have real-world impact.
If it is difficult to move assets between channels with provenance, one has to resort to cumbersome workarounds. Workarounds such as introducing “market makers” who sit between channels and maintain liquidity in both. But this has real costs: additional people to trust, additional fees, additional liquidity needs…
How is Corda different?
As I’ve written in other pieces, we spent a TON of time on Corda’s design: the data model, the fundamental conceptual framework and, critically, our solution to the thorny problem of how to assure privacy whilst allowing parties independently to validate chains of custody and other shared data… the essence of what makes a blockchain a blockchain and not just an expensive distributed database!
Our design addresses the problems in this article head on: data is shared at the level of individual deals or agreements or trades or contracts, with only the transactions needed to verify provenance being shared and no more. On top of this we layer anonymization and other privacy-enhancing techniques. These techniques build on top of each other. The need to prove provenance never goes away but we do our absolute best only to share the data that is needed to satisfy the recipient.
What’s more, we also built Corda to be able to use Intel’s game-changing SGX technology – without any changes to apps and with Corda’s famous developer-friendly programming model. So I was delighted that we could announce our partnership with Intel earlier this month.
I’m massively optimistic about the potential of blockchain technology to solve real problems in business. Just make sure you fully understand the pros and cons and different tradeoffs of each before making your selection: as always, one size never fits all.
Post-Script
I should stress that I have a boatload of respect for our friends at IBM – and elsewhere. I think channels are a poor architectural solution but I value immensely the collaboration we have via the Hyperledger Project (where we are both premier members) and beyond. And I look forward to deepening this collaboration further. There is more that unites projects such as ours than divides us!
And I should also point out that the Fabric team do know about these issues. For example, see this recent Stack Overflow question:
“How do we enforce privacy while providing tracing of provenance using multiple channels in Hyperledger v1.0?”
The answer is: “At the moment there is no straight forward way of providing provenance across two different channels within Hyperledger [Fabric] 1.0”.
And the answer goes on to reference a design document for a fix. That link is to a very long and complex design document. That tells me that the design problem may be pretty fundamental and can’t be fixed easily. But it’s good news that it is being looked at. We all benefit when platforms develop and evolve and I hope to see significant improvements in this area over time.
Update
2017-07-20
IBM’s Dan Selman has taken me to task about this post! He correctly points out that I didn’t say too much about Corda’s design:
This is because I’ve written about it extensively elsewhere but he’s right: I should have linked. This video from our Developer Relations team gives a pretty good overview:
And the other videos are pretty good too!
What that video doesn’t say (but should!) is the key point: in real-life scenarios, the dependency tree for any given transaction is invariably a very small subset of the overall set of transactions and so this technique (lazy on-demand provision of just the directly-required dependency tree and no more) gives us the optimal balance. It is enabled by the transaction design, where each transaction specifically specifies which previous state objects (“shared facts”, if you like) are being superseded. Put another way: we explicitly declare which parts of the shared state are being updated (actually, replaced) and so we know precisely which proof needs to be provided by one party to another.
In the Slack analogy, it would be equivalent to being able to automatically “lift out” just the pieces of a shared conversation that were directly relevant to the new person you wanted to add to the chat, without also showing them parts of the shared conversation that they have no need to see.