“Digital currencies” aren’t needed to explain why distributed ledgers are important.
In this post, I develop an argument for replicated shared ledgers from first principles. It is intended to be an “education piece” aimed at those, particularly in the finance industry, who prefer explanations of new technologies to be rooted in a description of a real-world business problem rather than beginning with a description of a purported solution. So, in this piece, you’ll find no mention of digital currencies, etc., because it turns out you don’t need them to derive an argument for distributed ledger technologies!
(Note to regular readers: see the end of the piece for some context)
We’ll start with banking systems
Start by thinking about today’s banking systems. In what follows, I use a bank deposit and payments example. But the same logic applies everywhere you look, as I’ll argue later.
Let’s imagine a world with three banks: Bank A, Bank B and Bank C and two customers, Customer A and Customer B. Each bank runs their own IT systems that they use to keep track of balances. This is a world very much like today.
So Bank A’s systems record the balances for Bank A’s customers, Bank B’s systems record the balances for Bank B’s customers and so on.
Perhaps the picture looks something like this:

Balances at three banks for two customers.
Two immediate observations jump out:
- First, look at Banks A and B. Bank A’s systems record that it is owed £1m by Bank B. And Bank B’s systems also record this fact: they record that Bank B owes £1m to Bank A. So the same information is recorded twice, by two independently developed, maintained and operated systems. And in other domains, this duplication is much greater and more expensive, as we’ll discuss below.
- Secondly, look at Customer A. They are owed money by banks A and C and are overdrawn at Bank B. Put another way, Banks A and C owe money to Customer A. Who records this fact? Banks A and C! We take this situation for granted but it does seem very odd that Customer A has to trust both that the bank will be good for the money and that the bank’s records will be accurate. That feels like a conflict of interest, if ever there was one…
So we have two interesting phenomena: deposit-makers have to trust their banks to be good for the money and to account for things correctly. And the banks themselves have to spend a lot of time and money developing systems that all do pretty much the same thing – and then spend even more time and money checking with each other to make sure their systems agree on common facts.
Even in our simple example, there are potentially 7 separate matching entries to be verified.
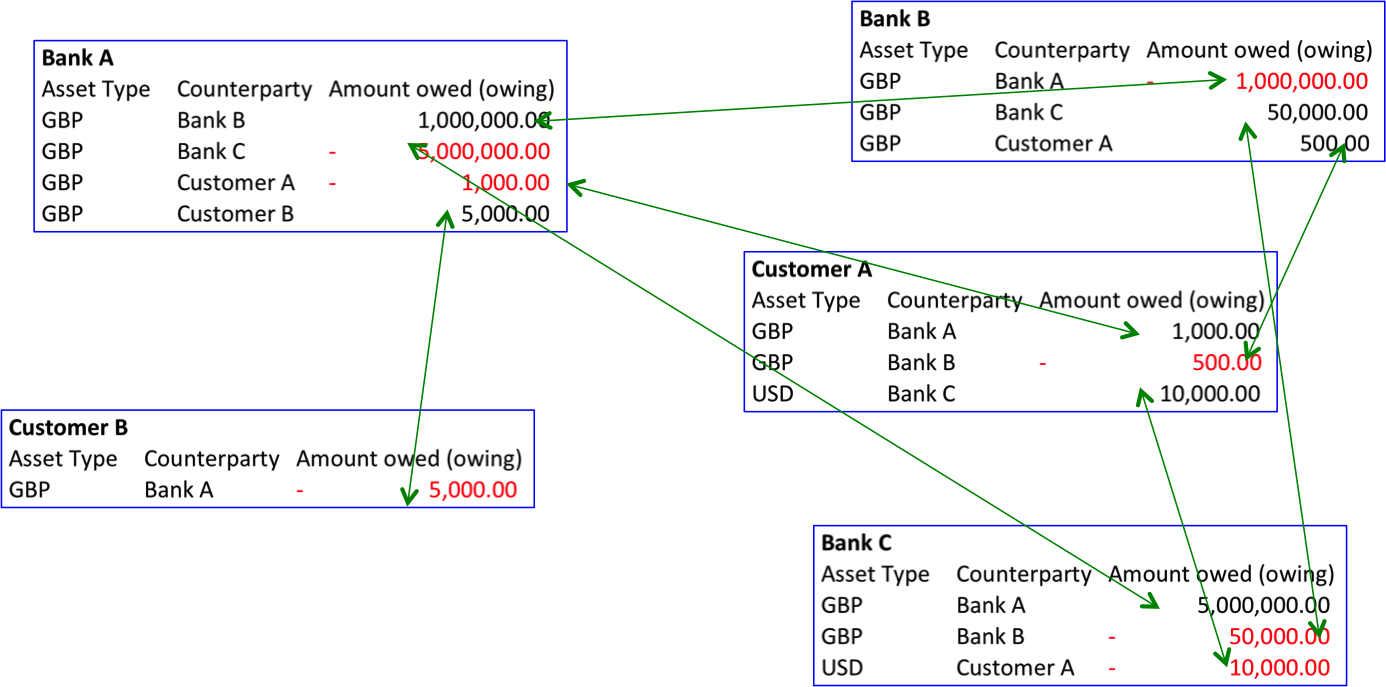
Banking “facts” are usually recorded by at least two different entities and an expensive process of reconciliation is needed to make sure each party’s view of the world is the same
It’s not just bank deposits. Securities and Derivatives Markets have the same pattern
This story is about bank deposits. But exactly the same story could be told about securities systems and derivatives systems. Indeed, in the latter case, the problem could be even worse: not only do we need to be sure everybody agrees on who has done which deals with whom, we also need to be sure that their systems agree on the resulting obligations that arise – they also have to agree on the business logic.
Think about how many near-identical systems exist across the financial landscape, each one working slightly differently and producing ever-so-slightly different results that have to be investigated and resolved. It’s hugely expensive.
Back to the banking story
But let’s focus on the banking example for now.
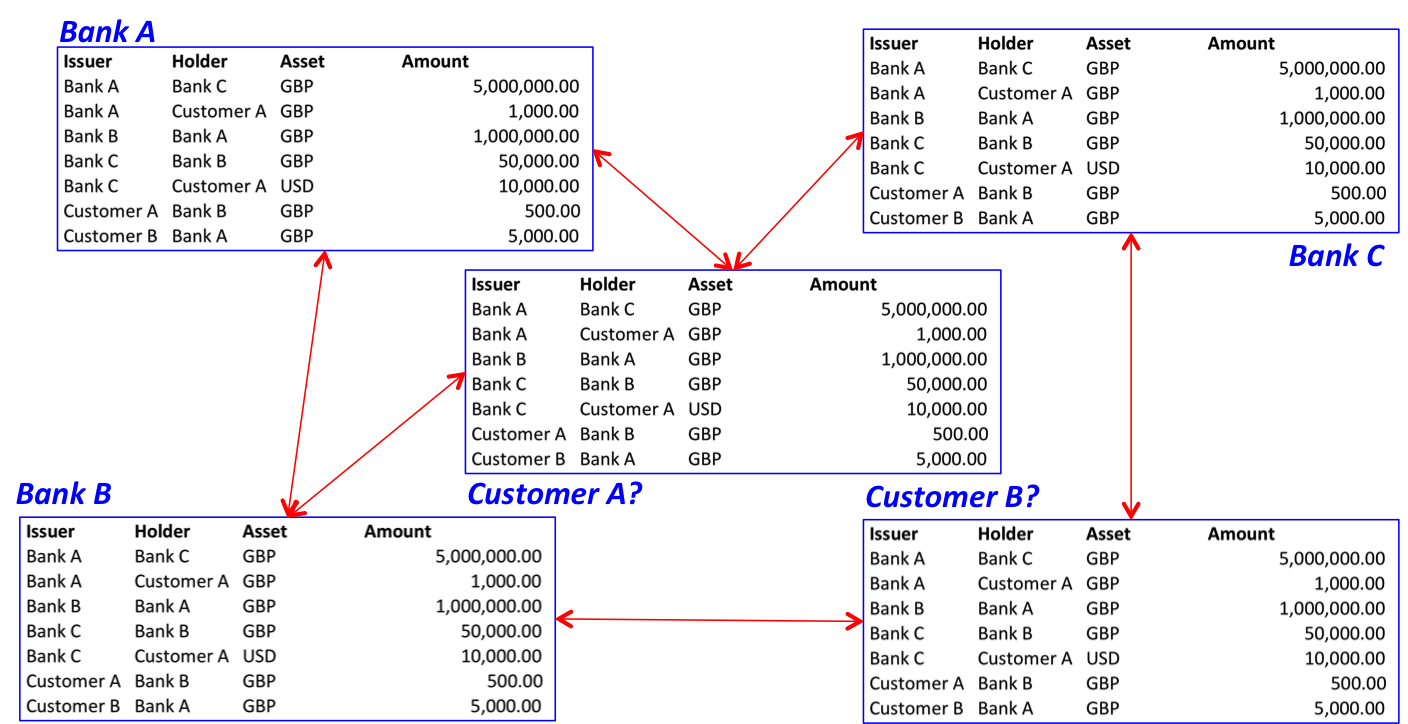
You can do something really interesting with the five ledgers we’ve been working with. You can write them a different way, with all the same information stored in a single table, rather than spread across five different tables:

The five separate ledgers on the left can be written, exactly equivalently, as the single table on the right – and vice versa. You can derive one from the other. The only difference is that the table on the right has an extra column so we can record both the issuer and the holder of a claim .
In other words, rather than having a partial view of the world held by each bank, we could have a single table that records everything and achieve the same outcome.
So why not just have a single banking ledger for the world?
This raises an interesting question. If it’s so expensive and complicated for each bank to run its own system that contains its own narrow view of the world – and then have to check it matches the other systems where the facts overlap – why not just pay somebody to run a single ledger that everybody agrees will be authoritative?
After all, as we showed above, any bank that wanted to could easily derive its own view of the world from this mega-table, completely trivially.
Of course, we’d have to give thought to how to mediate access to the ledger – who is allowed to observe or update which records – but we know how to do that… and it’s not an impossible problem.
Are you mad?!
Now, it is tempting to say that such a thing would be insane: imagine how powerful would be the firm who ran such a system. And imagine the catastrophic implications for the world if there was a system outage! Perhaps the expensive, error-prone, but fundamentally decentralised and robust (anti-fragile?) system we have today is a price worth paying.
But this means an interesting question arises: what if there a way to achieve the benefits of a globally shared system but without having to grapple with the difficult political question of how to control an all-powerful operator or how to deal with the risk of an outage of such an important, central piece of infrastructure?
Perhaps we can achieve this…
The Replicated, Shared Ledger
Remember what we achieved in the diagram above: we created a single table that could describe all bank balances and which was inherently shared: different actors had different permissions to update different parts of it.
But the worry in the section above was that a shared global ledger would be controlled by a single powerful entity and that this centralized system could be a systemic risk. So can we make two tweaks to the model?
- First, why not replicate the ledger massively. So, rather than one copy, have lots of copies. Perhaps one copy at every bank. So now there isn’t a single point of failure. We would have to worry about how those copies are kept in sync, of course, so this isn’t an unambiguous “win” but having copies at each bank might also make integration with existing infrastructure somewhat easier, too. Perhaps this would also help ease adoption.
- Secondly, why not have those who participate in the system – maybe just the banks or maybe their customers too – also be jointly responsible for maintaining and securing it. We know who everybody else is in this world, after all, so we know whom to punish if they cheat. So we replace a single powerful entity with a model where everybody contributes to the system’s security.
If so, perhaps the picture would look like this:
If a single copy of the global, shared ledger is undersirable or risky, then replicating it to all the participants could give the best of both worlds. Now the problem becomes one of automatically keeping the systems in sync rather than manually reconciling and dealing with breaks.
The picture above looks superficially like the one I drew at the start of the article. But there’s a critically important difference. In this model, all participants have a copy of the ledger but only have the right to amend entries pertinent to them. So it is both replicated and shared.
And so this is why I call this concept the “replicated, shared ledger”. I think this wording is better at evoking the right mental model than “distributed ledger”, for example.
And depending on whether you want to model balances, other assets or even agreements between parties, there are startups working on a project. I wrote a piece last year that attempted to make sense of the various players out there – and many more have emerged since then.
“Smart Contracts”
It it worth paying particular attention to the idea of adding business logic to this concept: so that the “facts” being recorded aren’t just who owns what but actual agreements between parties.
This opens up the intriguing possibility of “smart contracts”: a world where derivatives counterparties agree that a shared piece of code represents the agreement they have made with each other and they execute it on the shared, replicated ledger – perhaps completely eliminating the need to build, maintain, operate and reconcile their own proprietary derivatives platforms? Maybe even allowing the code to take custody of assets on the ledger, to manage cashflows and margin automatically?
Outstanding questions
But I should stress that this approach raises lots of technical questions: it’s not an unambiguously good idea. For example, do we know that the underlying replication technology works as described? Under all plausible threat scenarios? How can we be sure that one bank (or customer) can’t see (or amend…) another’s information? How much data would such a system hold? Would it scale? Is it really a good idea to model legal agreements in code rather than English?!
Conclusion
There do appear to be multiple examples of expensively duplicated systems in multiple areas of the banking system. The idea of a shared ledger holds promise, with replication by participants being a mechanism to reduce risk and mutualise its operation. But whether this argument holds in practice needs to be tested. So I fully expect to see more and more experimentation by banks and others in the coming months and years.
Thank you: I’m extremely grateful to Lee Braine for input/review of the logical argument in this post
Note to regular readers
For the avoidance of doubt, in the piece above, I was not talking about Bitcoin – I’ll post a separate follow-up that attempts a derivation for Bitcoin’s design given some plausible real-world requirements; this post is about the domain I sometimes call the non-“Bitcoin-like-world”, as defined in this post)
