“Digital currencies” aren’t needed to explain why distributed ledgers are important.
In this post, I develop an argument for replicated shared ledgers from first principles. It is intended to be an “education piece” aimed at those, particularly in the finance industry, who prefer explanations of new technologies to be rooted in a description of a real-world business problem rather than beginning with a description of a purported solution. So, in this piece, you’ll find no mention of digital currencies, etc., because it turns out you don’t need them to derive an argument for distributed ledger technologies!
(Note to regular readers: see the end of the piece for some context)
We’ll start with banking systems
Start by thinking about today’s banking systems. In what follows, I use a bank deposit and payments example. But the same logic applies everywhere you look, as I’ll argue later.
Let’s imagine a world with three banks: Bank A, Bank B and Bank C and two customers, Customer A and Customer B. Each bank runs their own IT systems that they use to keep track of balances. This is a world very much like today.
So Bank A’s systems record the balances for Bank A’s customers, Bank B’s systems record the balances for Bank B’s customers and so on.
Perhaps the picture looks something like this:

Balances at three banks for two customers.
Two immediate observations jump out:
- First, look at Banks A and B. Bank A’s systems record that it is owed £1m by Bank B. And Bank B’s systems also record this fact: they record that Bank B owes £1m to Bank A. So the same information is recorded twice, by two independently developed, maintained and operated systems. And in other domains, this duplication is much greater and more expensive, as we’ll discuss below.
- Secondly, look at Customer A. They are owed money by banks A and C and are overdrawn at Bank B. Put another way, Banks A and C owe money to Customer A. Who records this fact? Banks A and C! We take this situation for granted but it does seem very odd that Customer A has to trust both that the bank will be good for the money and that the bank’s records will be accurate. That feels like a conflict of interest, if ever there was one…
So we have two interesting phenomena: deposit-makers have to trust their banks to be good for the money and to account for things correctly. And the banks themselves have to spend a lot of time and money developing systems that all do pretty much the same thing – and then spend even more time and money checking with each other to make sure their systems agree on common facts.
Even in our simple example, there are potentially 7 separate matching entries to be verified.
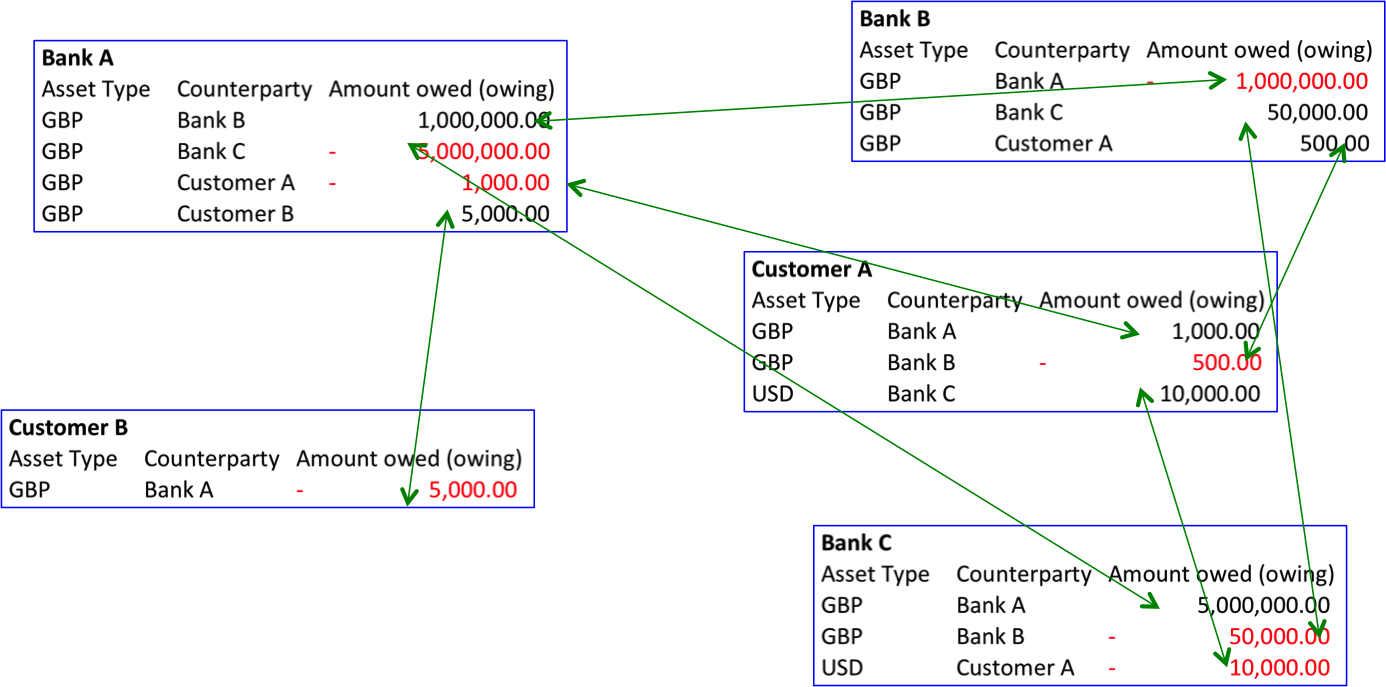
Banking “facts” are usually recorded by at least two different entities and an expensive process of reconciliation is needed to make sure each party’s view of the world is the same
It’s not just bank deposits. Securities and Derivatives Markets have the same pattern
This story is about bank deposits. But exactly the same story could be told about securities systems and derivatives systems. Indeed, in the latter case, the problem could be even worse: not only do we need to be sure everybody agrees on who has done which deals with whom, we also need to be sure that their systems agree on the resulting obligations that arise – they also have to agree on the business logic.
Think about how many near-identical systems exist across the financial landscape, each one working slightly differently and producing ever-so-slightly different results that have to be investigated and resolved. It’s hugely expensive.
Back to the banking story
But let’s focus on the banking example for now.
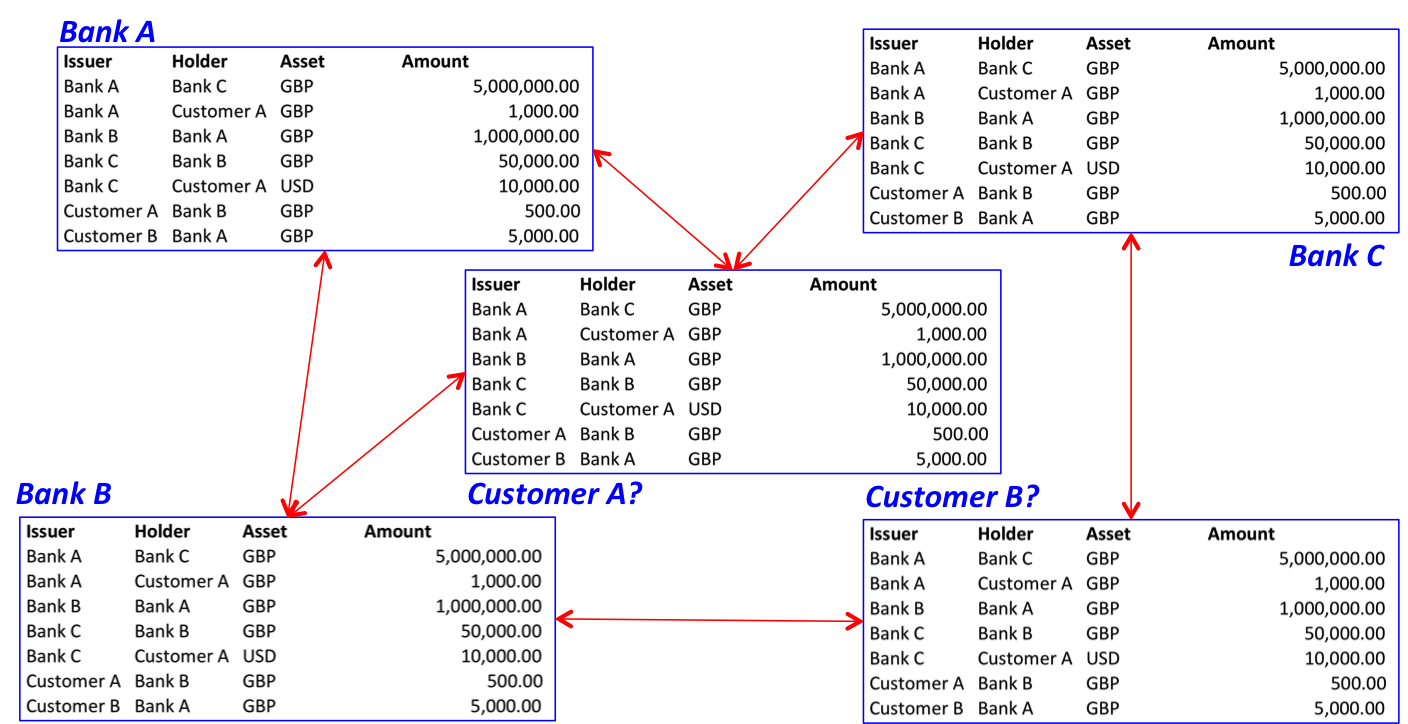
You can do something really interesting with the five ledgers we’ve been working with. You can write them a different way, with all the same information stored in a single table, rather than spread across five different tables:

The five separate ledgers on the left can be written, exactly equivalently, as the single table on the right – and vice versa. You can derive one from the other. The only difference is that the table on the right has an extra column so we can record both the issuer and the holder of a claim .
In other words, rather than having a partial view of the world held by each bank, we could have a single table that records everything and achieve the same outcome.
So why not just have a single banking ledger for the world?
This raises an interesting question. If it’s so expensive and complicated for each bank to run its own system that contains its own narrow view of the world – and then have to check it matches the other systems where the facts overlap – why not just pay somebody to run a single ledger that everybody agrees will be authoritative?
After all, as we showed above, any bank that wanted to could easily derive its own view of the world from this mega-table, completely trivially.
Of course, we’d have to give thought to how to mediate access to the ledger – who is allowed to observe or update which records – but we know how to do that… and it’s not an impossible problem.
Are you mad?!
Now, it is tempting to say that such a thing would be insane: imagine how powerful would be the firm who ran such a system. And imagine the catastrophic implications for the world if there was a system outage! Perhaps the expensive, error-prone, but fundamentally decentralised and robust (anti-fragile?) system we have today is a price worth paying.
But this means an interesting question arises: what if there a way to achieve the benefits of a globally shared system but without having to grapple with the difficult political question of how to control an all-powerful operator or how to deal with the risk of an outage of such an important, central piece of infrastructure?
Perhaps we can achieve this…
The Replicated, Shared Ledger
Remember what we achieved in the diagram above: we created a single table that could describe all bank balances and which was inherently shared: different actors had different permissions to update different parts of it.
But the worry in the section above was that a shared global ledger would be controlled by a single powerful entity and that this centralized system could be a systemic risk. So can we make two tweaks to the model?
- First, why not replicate the ledger massively. So, rather than one copy, have lots of copies. Perhaps one copy at every bank. So now there isn’t a single point of failure. We would have to worry about how those copies are kept in sync, of course, so this isn’t an unambiguous “win” but having copies at each bank might also make integration with existing infrastructure somewhat easier, too. Perhaps this would also help ease adoption.
- Secondly, why not have those who participate in the system – maybe just the banks or maybe their customers too – also be jointly responsible for maintaining and securing it. We know who everybody else is in this world, after all, so we know whom to punish if they cheat. So we replace a single powerful entity with a model where everybody contributes to the system’s security.
If so, perhaps the picture would look like this:
If a single copy of the global, shared ledger is undersirable or risky, then replicating it to all the participants could give the best of both worlds. Now the problem becomes one of automatically keeping the systems in sync rather than manually reconciling and dealing with breaks.
The picture above looks superficially like the one I drew at the start of the article. But there’s a critically important difference. In this model, all participants have a copy of the ledger but only have the right to amend entries pertinent to them. So it is both replicated and shared.
And so this is why I call this concept the “replicated, shared ledger”. I think this wording is better at evoking the right mental model than “distributed ledger”, for example.
And depending on whether you want to model balances, other assets or even agreements between parties, there are startups working on a project. I wrote a piece last year that attempted to make sense of the various players out there – and many more have emerged since then.
“Smart Contracts”
It it worth paying particular attention to the idea of adding business logic to this concept: so that the “facts” being recorded aren’t just who owns what but actual agreements between parties.
This opens up the intriguing possibility of “smart contracts”: a world where derivatives counterparties agree that a shared piece of code represents the agreement they have made with each other and they execute it on the shared, replicated ledger – perhaps completely eliminating the need to build, maintain, operate and reconcile their own proprietary derivatives platforms? Maybe even allowing the code to take custody of assets on the ledger, to manage cashflows and margin automatically?
Outstanding questions
But I should stress that this approach raises lots of technical questions: it’s not an unambiguously good idea. For example, do we know that the underlying replication technology works as described? Under all plausible threat scenarios? How can we be sure that one bank (or customer) can’t see (or amend…) another’s information? How much data would such a system hold? Would it scale? Is it really a good idea to model legal agreements in code rather than English?!
Conclusion
There do appear to be multiple examples of expensively duplicated systems in multiple areas of the banking system. The idea of a shared ledger holds promise, with replication by participants being a mechanism to reduce risk and mutualise its operation. But whether this argument holds in practice needs to be tested. So I fully expect to see more and more experimentation by banks and others in the coming months and years.
Thank you: I’m extremely grateful to Lee Braine for input/review of the logical argument in this post
Note to regular readers
For the avoidance of doubt, in the piece above, I was not talking about Bitcoin – I’ll post a separate follow-up that attempts a derivation for Bitcoin’s design given some plausible real-world requirements; this post is about the domain I sometimes call the non-“Bitcoin-like-world”, as defined in this post)

Now that’s an interesting one, to make a parallel with the payment world (not Bitcoin), it would be like running Mastercard without actually having Mastercard the company or maybe a much lighter version of it. Ad hoc “blockchains” are very interesting in multiparties B2B environment (as trust can be supported by other means – legal for example) because they truly enabl a new way to interact, collaborate and trade more akin to a guild than an intermediation by a central party.
Good work..
Looks very much @Ripple outlined without naming it ..
@Yann – good point. Perhaps “guild” is the way to think about it…. What I had in mind when I wrote it was the idea of a shared structure that avoids the principal/agent problem you get when they simply create a standalone, separate company that they all just happen to own.
@marc – Ripple is certainly one example of this (I mention them in the post I link to where I talk about multiple projects in this space). But they’re not the only one.
Reblogged this on Preston Byrne.
Ideas about sharing transactions and ledgers between counterparties seem to go back to the late 1990s. Todd Boyle wrote about triple entry in which he was expressing the hope that a third party would hold the transaction record(s) as well as the two interacting parties, in order to establish certainty in transactions.
Contemporaneously (?) Wei Dai went further and wrote “every participant maintains a (seperate [sic]) database of how much money belongs to each pseudonym.” As such, he more or less laid out the design that became Bitcoin a decade later, which is no mean feat.
Yet, Boyle disagreed: “I am not saying public; I am saying shared. The amount, date and description of a deal are inherently shared between two parties and should be stored visible to those two parties alone, i.e. either protected by private system permissions or, encrypted visible to those two parties alone.” And we’ll likely find that most all businesses and individuals agree with Boyle, not Wei Dai, if they’re given the choice.
So how did this bifurcation in thought processes occur? I suspect it comes down to threat models. If as David Chaim and Satoshi Nakamoto thought, you think that the state and/or the bank is your biggest enemy, then you are likely all for decentralisation because any center is a place for the devil to undermine you on the details. On the other hand, if you are in business or have more than a decade’s experience in relationships, you might think that your biggest enemy is your future ex-partner-turning rogue. In which case, having a neutral third party to back you up on what really happened is your primary concern, and everyone else can bow out of the dispute, thanks very much.
Back in the old cypherpunks days, they used to say on every second post: YMMV or your mileage may vary… These days, we’re more likely to say, all of these problems go away with liberal doses of SNARKs, homomorphic encryption and magic unicorns.
Good piece – a few comments.
Deposits are liabilities on a bank’s balance sheet, the corresponding double-entry is cash, an asset, so if a bank claims it doesn’t owe you money, it also claims it doesn’t have the corresponding cash! Therefore, there’s not much of an incentive for banks to misreport deposits, and indeed, having audited quite a few banks I’ve never come across this or heard anecdotally that this is a problem. The old-school compensating control was a customer held checking book that recorded all deposits and withdrawals – no need for complex distributed systems!
Maintaining separate accounting records and subsequently reconciling them is a massive pain but it is something that we are getting better at through automation. Sharing data definitely helps.
The way I see the above working is autonomously, securely and privately sharing data with counter-parties (entities which have an incentive to keep records, e.g. not most individuals) to produce agreed shared ledgers. By shared ledgers, I specifically mean bilaterally shared ledgers only. Public ledgers are a massive no-no for compliance and privacy reasons. E.g. reporting unaudited financial data for most entities is in no-one’s interest.
Under the above scheme, one entity’s asset is anther’s liability, therefore in this zero sum game, creating fictional records means someone, somewhere has to hold a liability. Under proper management, no entity will sign off on a liability unless it 100% exists, is measurable and the obligations to pay are unambiguous. That said, simple detective controls are enough to weed out fake records in the bilaterally shared ledger. No need for distributed consensus.
A bunch of third parties (maybe randomly selected participants or a regulator / trade body) can maintain transaction confirmations. The existence of digital signatures ensure that no one party can repudiate on an obligation.
Once a transaction is complete / settled and reported upon, there is no need to keep the shared record – it can be discarded or archived.
Cheers
Hi Richard,
This is a great way of progressively explaining these decentralized ledgers, but I’m wondering:
– what is the banks’ incentive to make these types of changes (which seem radical to them)
– furthermore, the benefits will accrue obviously they all go along a similar direction (more or less), so that makes the changes even more daunting.
I’m just curious as to your thoughts regarding a potential implementation scenario (if there is one).
Great post and way of looking at it, but I’d take it further. Blockchains can be used as a method of managing validity, synchronisation and permissions for any general purpose multi-table database schema. Consider the UTXO set in a bitcoin-style blockchain to be the equivalent of the rows in a set of database tables, where (optionally) each row defines its own permissions. A blockchain is a method for ensuring that no row/UTXO can be deleted or modified more than once (where we consider the modification of a row as the deletion of that row and its replacement with a new row, a la MVCC). Generalize a blockchain’s spending rules into any function which evaluates the validity of a transaction which maps from (old rows + some input) -> (new rows), and we can apply pretty much any application level constraints, including permissions, at the database level.
@iang – thanks, as always. There’s nothing new in the world, is there… I think your analysis is probably right: if you take my simplified model of a table recording issuers/holders of assets, my working assumption is that the minimal privacy/confidentiality solution you want is: “issuer can see everything they’ve issued; holder can see everything they hold; nobody else can see anything” (or something sufficiently formal that captures that notion). So a fully public ledger fails this test, as indeed does a private one where all participants can see other participants’ balances, etc.
So one can imagine three paths forward: 1) don’t worry about it – e.g. rely on obscurity (the bitcoin model?) or agreements not to misbehave (just as risky?), 2) an advanced technical approach based on homomorphic encryption, etc, 3) a federated/multi-level approach where a *set* of ledger-operators are paid (and trusted) to hold/maintain the full copies, with participants subscribing to one or more for restricted feeds. Do you see any others?
@roger – great… thanks for the comment… exactly the sort of debate I was trying to trigger. So you’re agreeing with Ian’s characterisation of Boyle’s position in the post above yours right?
I should point out for the benefit of others, however, that I was using the ‘simple’ banking example to motivate an argument and I suspect the real prize (in terms of complexity reduction) could be with scenarios with complex business logic (e.g. derivatives, etc). But your point could still stand.
@wmougayar – great questions. Building on my response to Roger, my sense (theory?) is that there probably isn’t a huge need/incentive to do anything in the deposit/payments space (except, perhaps, for some of the international payments use-cases Ripple are exploring?). But there could well be sufficient cost/complexity/risk/duplication elsewhere to make it worth exploring.
“If it’s so expensive and complicated for each bank to run its own system that contains its own narrow view of the world – and then have to check it matches the other systems where the facts overlap – why not just pay somebody to run a single ledger that everybody agrees will be authoritative?”
Because people disagree on how wealth should be distributed, and who owns what. The original Ripple proposals contained the option for multiple disagreeing limits and amounts to exist on a single connection.
It’s a little less obvious than with physical property (I can’t wait until Ethereum starts being used to represent ownership of real estate on the order of magnitude where Israel/Palestine get to bicker over who gets to own what first), but the root issue is still there: somewhere, someone has to define who has the value that the ledger distributes. Unless the shared ledger contains mutually contradictory information(it’s possible to design one that does) there’s going to be different groups who have different interests in making these kinds of values talk to eachother.
The conflict of interests inherent in the conflating of storing of value and accounting for said value is very real. Separating the two might help, a lot. But in doing so we should be wary that there may be inherently predatory relationships that are implicit in treating the banks as the only authoritative source of where this kind of information comes from.
@jeff – interesting – thanks. Do you have any links to discussions/docs about the older ripple model that you mentioned please?
https://groups.google.com/forum/#!forum/rippleusers is where much of the old stuff happened
How is it possible to enable a decentralised globally distributed zero-trust block chain system without some form of value token which acts as the incentive to the mining process which is what provides all transaction verification and network security ? In a globally de-centralised zero trust consensus ledger surely the two are intrinsically connected and cannot be separated unless you are talking about a centrally controlled trust based system. Is that what you are referring to ?
@jeff – thanks.
Hi @T.Wayre – Where in the article was I talking about a “globally distributed zero-trust block chain system”? I explicitly assumed a world where we *know* who the participants are and where we have the ability to punish/motivate them using mechanisms extrinsic to the system. i.e. I’m *not* describing the threat-model or use-case that systems like Bitcoin address.
Reblogged this on golfing eagle.
Hi Richard,
If you the benchmark you are comparing e-cash against is fiat cash then I am not sure if this conclusion is valid : “If you want true electronic cash, there can’t be an issuer. So the asset has to be native to the platform”
Cash does not have censorship resistance, and it has issuers – central banks. If a digital ledger prevents any party other than a central bank to issue e-cash in the first place then all subsequent transactions within the ledger do not need to be validated by the issuing central bank. Central banks cannot apply any more selectivity to honoring this e-cash than they do it with cash.
Is there any flaw in my reasoning above?
Thanks,
Ram.
@Ram – thanks for the comment. I agree that physical cash has an issuer (the central bank, as you say). But I’d disagree with your comment that it doesn’t have censorship resistance. Perhaps we’re using different definitions? i.e. I can hand physical cash to anybody I choose, and nobody can stop me. That’s what I mean by censorship-resistance. But I’m happy to accept that I may be using a definition that’s different to everybody else’s! What’s your definition?
As for e-cash, I agree with you that one could design a ledger that works in the way you describe (single issuer: the central bank, but no ongoing validation/approval). But could it be built that way in reality? I would argue no. For e-cash to trade at par with physical-cash, you would need absolute certainty of convertibility… that you could return e-cash to the central bank in exchange physical money. And do we really believe that would be true? Government would (probably quite legitimately) insist on various compliance checks. There would be people who tried to convert their e-cash to physical cash, only to be told “sorry, no”. Similarly, do we really believe that a court wouldn’t order the operator of such a system to “freeze” individual accounts (or, equivalently, order the central bank not to redeem coins that have been held by certain accounts) under various scenarios?
In other words, my argument is: yes… you can build an e-money system on an electronic ledger and it would be extremely useful (cf m-pesa, etc). But it wouldn’t have the properties of cash, at least not as I defined it in my piece.
But it does, I think, explain why Bitcoin works the way it does… because they were explicitly trying to design a system that *does* have most of the properties of cash… and the only way they could do it was by introducing their own currency unit… you simply can’t get it to work if there’s an identifiable issuer – central bank or otherwise – as part of the architecture. This is also why I included the comment about most people not sharing the objectives of the Bitcoin designers… it solves a difficult problem in a very interesting way… but it’s not necessarily a problem that most people actually think they have in real life!
Reblogged this on Scarabocchi and commented:
Finally, a coherent explanation of distributed ledger technology aka the blockchain.
Hi blogger, i must say you have hi quality content here.
Your blog should go viral. You need initial traffic only.
How to get it? Search for; Mertiso’s tips go viral
Hello gendal,
This is Ajian, from Ethfans.org, which is a China based Ethereum developer community, dedicating to promoting Ethereum and blockchain technology in China. One of our main projects is translating selected English posts into Chinese and circulating them on our website and newsletters, where we have more than 8000 daily visits.
I am wondering if we can ask your authorization to translate this post for non-profit purpose. If permitted, the Chinese version will be posted on ethfans.org and our wechat daily newsletter. We will specify your authorship of the post, and put down a link to your original post.
Please let me know if you have other requirements regarding the authorization. Looking forward to your reply.
Thank you.
Best regards,
Ajian
Hi Ajian – thanks for asking! I’d be very happy for you to do this if you 1) send me a link afterwards and 2) include a link and commentary about how I now work for R3 and the result of my work is the open source Corda platform (link to https://corda.net). It would be great if your readers were able to learn about other approaches in addition to Ethereum! Thanks again for asking.
Teach me i want sukses ..