Don’t Say The “B Word”!
I’ve come to the conclusion that saying “blockchain” has become unhelpful. It just confuses people. It means too many different things to different people and so it’s almost impossible to have a conversation in this space without talking past each other. So, as I argued in this piece on permissionless ledgers and this piece on permissioned ledgers, it can be useful to talk in terms of replicated shared ledgers – since I think this gets to the heart of what unifies – and separates – these two worlds.
- Shared: because multiple actors can read or write to different parts of the ledger
- Replicated: because everybody who needs a copy can have a copy, rather than relying on a powerful central entity
In this piece, I try to bring it all together – to explain why we should be thinking about permissionless ledgers as a classic example of disruptive innovation and how I think banks could think about permissioned ledgers in the interim.
In what follows, I build up the model below from its constituent parts:
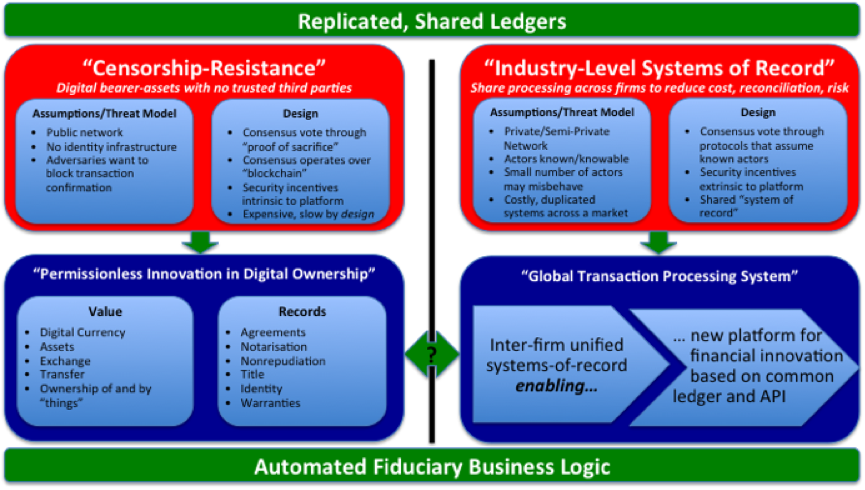
A unified model of permissioned and permissionless ledgers?
Permissionless Ledgers: Censorship Resistance
Let’s be clear: the breakthrough of Bitcoin was to create the closest system yet of “digital cash” – something that you can own outright and transfer to anybody else without permission. Its design flows naturally from that objective:

Bitcoin’s design follows directly from its objectives. Its replicated, shared ledger is designed to enable the existence of a censorship-resistant digital bearer asset
As I argued here, it’s little surprise that bankers and regulators look at it with deep suspicion! However, there’s a good reason why the smart observers aren’t dismissing it: censorship resistance implies an open, neutral platform that could be a driver of permissionless innovation:
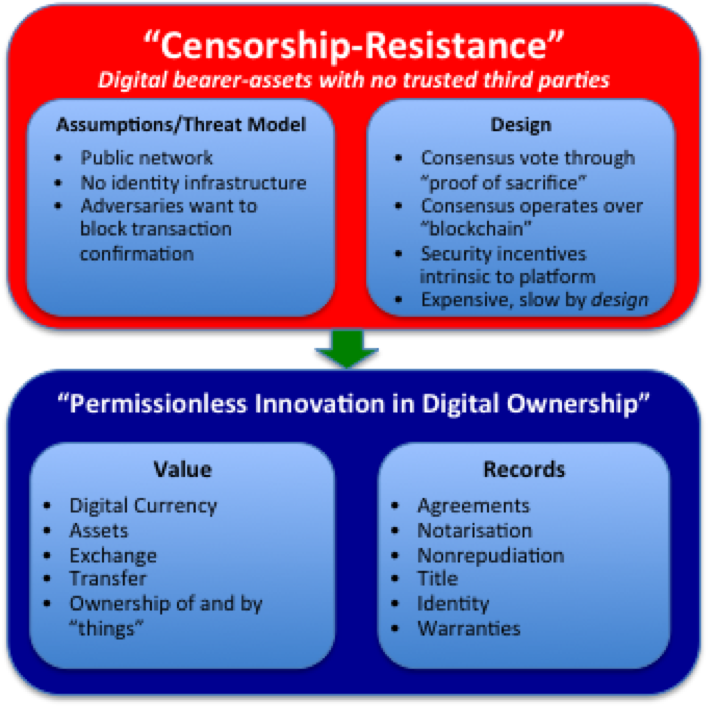
Censorship-resistance enables permissionless innovation in digital ownership
So, it’s not a surprise that we’re seeing innovation and experimentation in the fields of value transfer – such as micro-micro payments (nanopayments?) for video content – and in the recording and execution of agreements. This is, almost but not entirely, exclusively being driven by people from outside the traditional financial sector. They’re taking a platform that is, in most meaningful ways, slower and more expensive than today’s financial system and using it for novel purposes.
I think the smart firms are keeping an eye on this because they know how stories like this end:
“Disruptive innovations usually find their first customers at the bottom of the market: as unproved, often unpolished, products, they cannot command a high price. Incumbents are often complacent, slow to recognise the threat that their inferior competitors pose. But as successive refinements improve them to the point that they start to steal customers, they may end up reshaping entire industries” (The Economist)
Permissioned Ledgers: Industry-Level Systems of Record
Notwithstanding the promise – or threat – of permissionless systems, I sense that many financial firms are looking closely at permissioned systems, by which I mean technologies that allow multiple firms to run a private, shared ledger of some sort. What most people fail to ask is: why?! If you don’t have censorship-resistance as your business objective, why are you looking at this space at all?
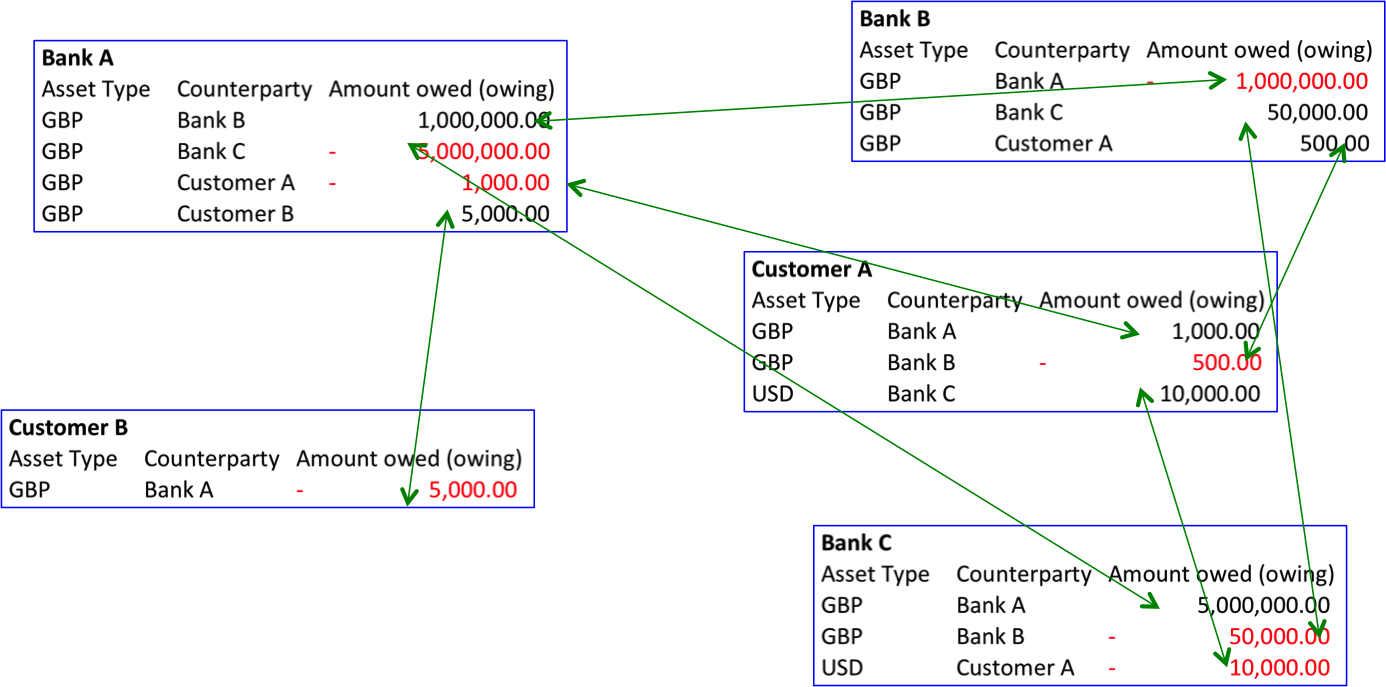
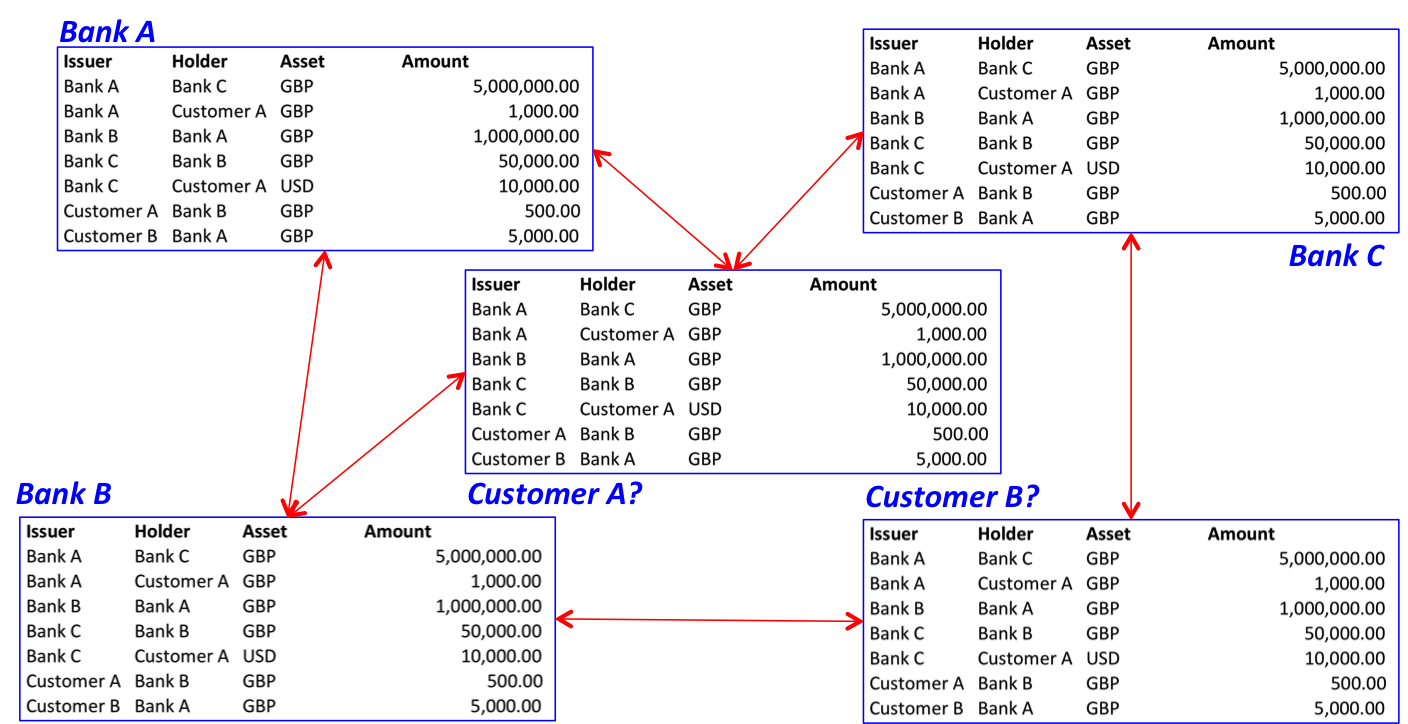
The answer, I argued, in this piece is that replicated, shared ledgers can also solve a different problem: if you’re in an industry where multiple firms all run similar systems to keep track of records (account balances? derivatives positions? orders?) then you’re probably carrying cost you don’t need: everybody is paying to maintain these duplicated, non-differentiating systems. And, because they’re all slightly different, you need to reconcile them with each other all the time to make sure they agree.
So the argument for applying replicated, shared ledger technology to this problem is that you could mutualise the cost of running and securing a single logical ledger, copied across your firms so you each have your own copy and so aren’t reliant on a powerful central entity for access. So nothing to do with censorship-resistance and nothing to do with cryptocurrencies. The idea, instead, is to move from each firm having its own systems of record to having systems of record at the level of the industry:
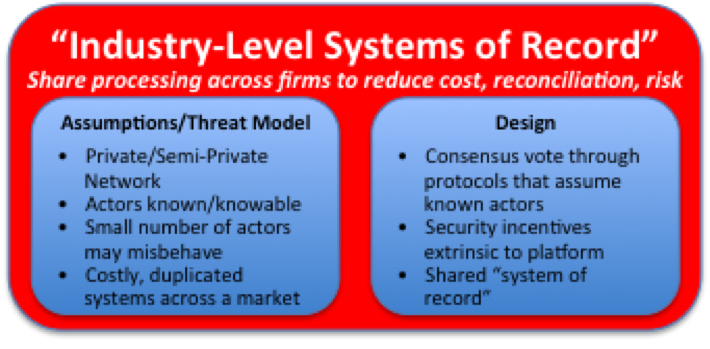
Is the promise of permissioned ledger the possibility of industry-level systems of record without a powerful central gatekeeper?
But we can take this thought-process further. Imagine such a platform existed: perhaps a replicated shared ledger that recorded all inter-bank balances or recorded all derivatives positions between firms. What we would effectively have is a transaction processing system for that industry: if we all agree that this shared ledger is authoritative for records (e.g. who owes what to whom) then could we not also agree that this ledger is something to which we could deploy code that describes our agreements? Could this industry-level ledger also host inter-firm business logic? How much cost and complexity might that remove from firms?
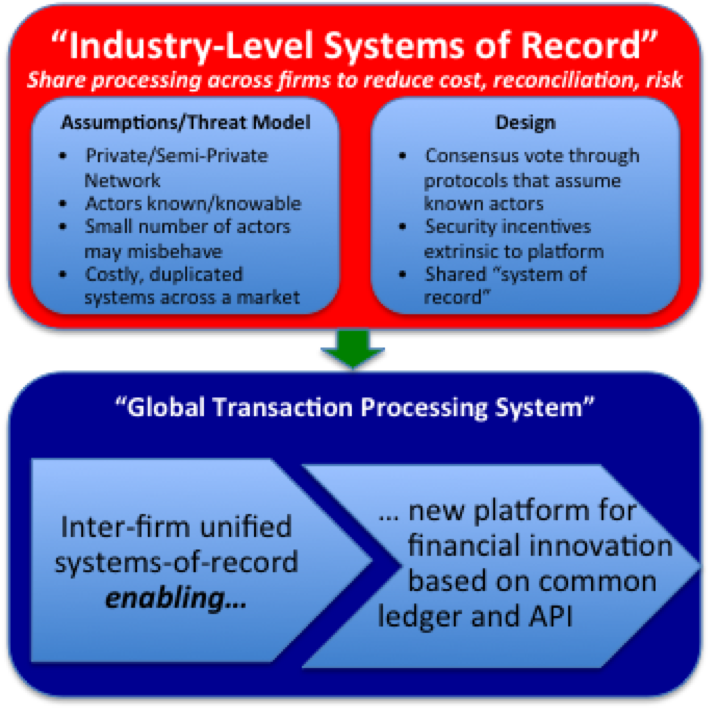
Is a common ledger between firms the enabler for a common transaction processing platform for an industry?
And this is where, I think, the two worlds – those of permissioned and permissionless ledgers – come back together:
Unifying the worlds of permissionless and permissioned ledgers
In the permissionless world, some of the most interesting developments are happening at the level of transaction scripting and smart contracts. The Ethereum project is the most obvious example, of course, but even projects like Streamium are showing how Bitcoin features can be used to create interaction models that simply aren’t possible on today’s financial platforms.
Similarly, and as I argued above, the driver of innovation on permissioned ledgers might be the migration of inter-firm business logic from individual firms to a shared ledger between firms: think of code that represents an agreement between two firms, that executes “on” a ledger, which can take custody of assets on that ledger and execute in response to external events: if both firms have signed it off in advance, suddenly they don’t need all the cost and expense of their own systems. I wrote about this idea in my piece on smart contracts.
So we see that the two worlds of replicated, shard ledgers – permissioned and permissionless – might actually be leading us to the same place: a world where business logic for money – automated fiduciary code, if you like – is deployed to a shared ledger and run autonomously.
Perhaps the permissioned and permissionless worlds aren’t as different as they seem?