Everybody I ask has a different definition of a “smart contract”; Here’s mine.
I hear more and more people talking about “smart contracts” these days. But when you push them to define the term, the concept often dissolves in their hands.
This isn’t a new observation: Peter Todd made a similar point after sitting through a session at a workshop we both attended last year.
Indeed, I was almost certainly one of the many who failed to impress him that day 🙂
Now, of course, one answer is to simply point at the intellectual visionaries who foresaw this space decades ago. Nick Szabo’s Smart Contract piece from 1997 is a really succinct and helpful overview. And I really like Ian Grigg’s idea of the “Ricardian Contract”. Szabo’s “vending machine” model is particularly helpful.
But these ideas predate the world of Bitcoin, blockchains and cryptocurrencies and so it’s not immediately obvious for new people in this space how to bridge the gap. Worse, there are multiple platforms out that purport to implement smart contracts. Indeed, you can argue that Bitcoin itself is actually a smart-ish contract platform. So it becomes even harder to distinguish between the concept and a specific implementation.
In this piece, I try to build a motivation for why something like a smart contract might be a nice idea and use that to produce my definition and model.
The Replicated, Shared Ledger
When I think about block chains and distributed ledgers, I start with what I think is the key innovation of Bitcoin: it taught the world how to transfer value at-a-distance with no trusted third party. (Yes: I know some people take issue with this and it may not be 100% accurate – but I think it creates the right intuition)
Sure – we could hand physical money to each other face-to-face but, until Bitcoin, there was no way to send value to somebody on the other side of the world without having to trust centralized third parties: the postal service, banks and so forth.
It’s as if the traditional money-movement infrastructure of banks and payment systems had been reimagined as a flat peer-to-peer network of actors. Perhaps moving from the picture on the left to the picture on the right:
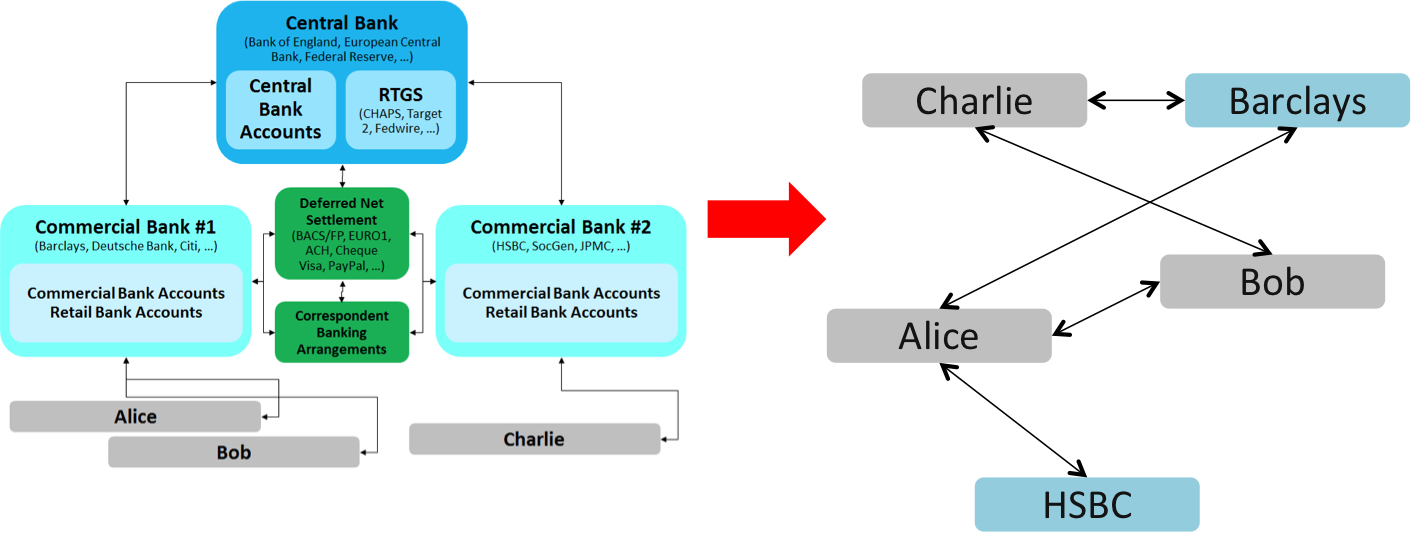
Bitcoin opened the possibility of peer-to-peer electronic value transfer, in contrast to today’s system of banks, central banks and payment systems. [I use these Banks merely as examples; I’m not trying to imply they’re doing anything in this space!]
But what this (very naïve!) picture misses is precisely how systems like Bitcoin achieve their claims.
The answer is that Bitcoin-like systems are built on things that I’ve started calling “replicated, shared ledgers”. That is: every full participant in the network has a full copy of the transaction ledger and the “magic” of the system is in how it makes sure that everybody’s copy stays in step with everybody else’s.
So, perhaps the correct picture is this one on the right below, where each participant is shown as having access to the same shared, replicated ledger:
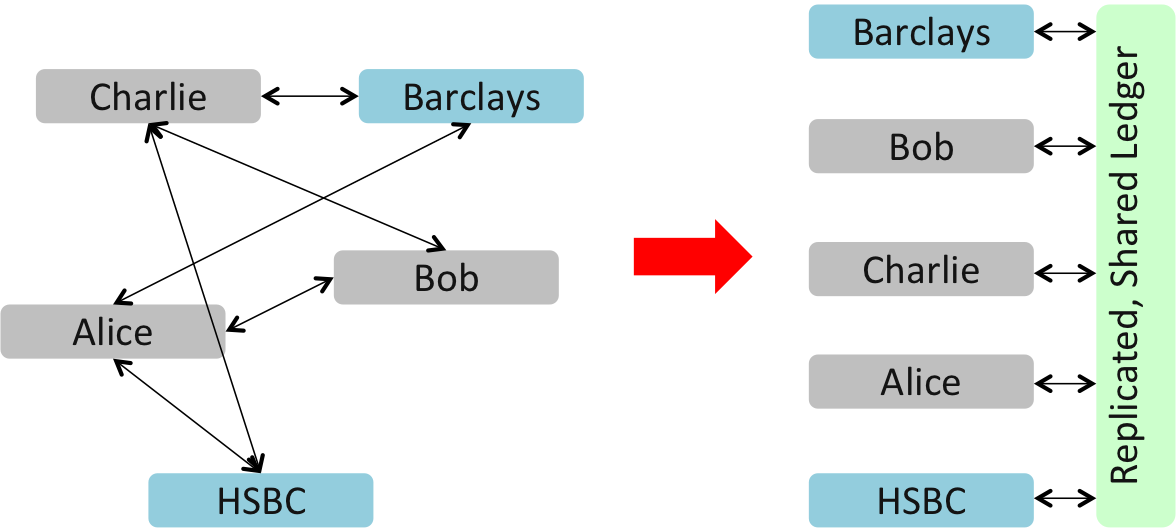
The trick of Bitcoin and other decentralised consensus systems is in how they ensure everybody has a copy of the ledger that they know is in step with everybody else’s
Great – leaving aside questions of scalability and so forth, we can see that this architecture can work: if everybody has the same copy of the ledger as everybody else then you no longer need central entities to keep track of who owns what (or who owes what to whom). Instead, you know that when your ledger gets updated to record a change of ownership of an asset then everybody else’s does too.
We need to distinguish between what the ledger records and how it does it
A great deal of the debate and competition in this space is focused on how this ledger is structured and secured. Bitcoin’s mining algorithm? Ethereum’s system? Ripple’s consensus algorithm? What these debates often miss is that these are all “how” questions: how is the ledger secured? How does the consensus process work? How are bad guys kept at bay? And they’re all different because the platforms make different assumptions about the nature of the threat they are likely to face.
But, for this article, it’s useful to forget that side of things for now and, instead, ask yourself: what does this ledger record? What is it used for?
What does this ledger record?
In one of my recent posts, I explored how this concept of a “shared, replicated ledger” could have application well beyond currency. My point was that once you know for sure that your view of the world is the same as everybody else, it opens up new possibilities in entirely unrelated areas, perhaps even accounting. Ian Grigg has written about this and firms such as triplentry are exploring it today.
One of the driving thoughts here is: if I know that everybody “sees” the same things as me then perhaps I don’t need to spend so much money building my own custom ledgers and perhaps I don’t need to spend so much money auditing and reconciling with everybody else… the ledger does it for me.
OK – so perhaps a shared, replicated ledger could take cost and duplication out of today’s commercial systems.
So where else do we have duplication?
One area is in business logic. There are countless examples in business where two (or more) parties to a contract each independently write computer systems that model the terms of that contract. I sometimes get accused of only talking about banking examples so here are some non-banking examples of what I mean:
- Large online retailers probably have a system that checks the bill they receive from their delivery companies is correct: have all the negotiated discounts been applied?
- Large grocers negotiate complicated rebates from their suppliers, based on volumes in a period and plenty of other factors. You can be pretty sure that both sides of those contracts have developed very sophisticated models of the contract in computer code
- A surprisingly large number of consumer insurance policies in the UK are sold through brokers. These brokers typically use software platforms provided by third party firms. These third-party platforms usually have their own implementations of each insurer’s pricing model: it is not unusual for a single insurance product to be represented in three or more completely independent code bases!
What unites these scenarios and countless others like them is that each party needs an independent means to calculate the value owing (or owed) under the contracts. They can’t realistically trust the other side. So logic dictates that they each have to build their own system. This might be wasteful and drives a need for reconciliations and so forth.
But think back to what I said above: a replicated, shared ledger has the property that everybody knows that everybody else is seeing the same thing without one side having to trust the other side to be scrupulously honest.
So imagine, now, that your ledger could also run computer code. Here’s what you could do:
- When you negotiate an agreement with somebody, you also agree on a representation of that agreement in computer code
- You agree what information sources it will use for external data and how disputes will be resolved
- You both examine the code in detail to confirm there are no secret backdoors or sneaky loopholes. And you perform testing to check it yields the right answers for the various inputs your provide to it.
- Satisfied that it does what you want it to, you both sign it and deploy it to the ledger.
And now you have something really interesting: neither of you have to go to the effort of reimplementing the terms of the contract in your own systems: you both know that this single piece of code satisfies both your purposes. And because it is running on this shared, replicated ledger and using it as its source of information, you can both be sure that whatever the program outputs will be the same for both of you.
Indeed, supervisory authorities, in time, may come to insist that this is how some business is done.
But we can go even further
So far, I’ve outlined a fairly mundane scenario: a computer program that represents the agreement between two or more parties.
But remember: we’re imagining a world where this program runs on the shared, replicated ledger…. the shared, replicated asset ledger.
What if this program could interact with that ledger? The program could take control of assets on the ledger and you could even send assets to the program. So it’s no longer just a computer program, it’s an economic actor in its own right.
Imagine we’re in the grocery scenario: you could imagine the grocer paying its suppliers by sending payment to this computer program. The program could calculate how much rebate is likely to be due, send the difference to the supplier as payment for the goods but temporarily hold on to the rebate – since we’ll only know for sure at the end of the month what the true discount percentage should have been. At this point, the contract could send the right amount of remaining funds to each party.
It’s as if this program isn’t just a computer program: it’s an actor in its own right. It responds to the receipt of information, it can receive and store value – and it can send out information and send out value.
It would be just like having a human who could be trusted to look after assets temporarily and who always did what they were told.
And this idea is what I think people mean when they talk about Smart Contracts.
The diagram below is my model for this: a piece of code (the smart contract), deployed to the shared, replicated ledger, which can maintain its own state, control its own assets and which responds to the arrival of external information or the receipt of assets:

My mental model for a smart contract: a computer program that runs on a shared, replicated ledger, which can process information, and receive, store and send value.
So much for the theory
So that’s the essence of it, I think. Perhaps more formally, my definition might be that:
A smart-contract is an event-driven program, with state, which runs on a replicated, shared ledger and which can take custody over assets on that ledger.
But that’s just my working definition. And there are lots of conceptual issues. I summarise some of them here, merely as signposts for further study (and future posts)
- Injecting Real-World State
- Smart contracts rely utterly on the quality of the information which is sent to them. “Oracles” and “n-of-m” schemes can help. But where I think additional thought is required is in what happens when things change: what happens if information sources go away, if previously independent sources merge, if new and better sources emerge?
- Modelling
- There may prove to be examples of business problems that can be modelled in multiple ways – e.g. directly as assets on a ledger or as contracts. Perhaps good practices need to emerge for the “right” way to model different types of real-world phenomena
- Dealing with bugs, errors
- Have you ever written a computer program without bugs? So how would one fix a smart contract once deployed if the bug is clearly in the favour of one of the parties?
- Could this also be the early days of a new profession? Just as lawyers can earn big money finding loopholes in contracts, will there be a cadre of “engineer-lawyers” looking for loopholes in smart-contracts?
- Liquidity
- If assets are under the custody of a smart contract, they are, by definition, not available to anybody else. This could change the economics of various businesses.
- Legal validity
- Does a smart contract have the same legal force as a “real” contract? What happens if the output of the contract is incompatible with law or a court finds it to conflict with the English-language version of the agreement? Does it depend, in part, in how the ledger is secured?
- Privacy
- Most shared, replicated ledgers are public. I don’t know many retailers who want their deals with their suppliers to be public knowledge
- Technical
- Does the underlying technology work satisfactorily? Does it scale? And so on
- … and much more
But I’m pretty sure smart people in the community are looking at all of these things. So perhaps the real test is: what are the compelling business scenarios that will drive adoption/experimentation in this space?
If you’ve reached this far, well done. I’d urge you to study the writings of Szabo, Grigg and countless others on this… they’ve covered this space so much better than me…
