Could decentralized ledgers change the face of accounting?
When I speak to people about decentralised ledgers, some of them are interested in the “distributed trust” aspects of the technology. But, more often, they bring up the question of cost.
This confused me at first. Think back to where this all started: with Bitcoin. Bitcoin is deliberately less efficient than a centralized ledger! Its design adds really difficult engineering constraints to what we already had. How could this technology possibly be cheaper than what we already have?
And yet the claims keep coming. So perhaps this “cost” claim deserves closer consideration. Perhaps there are some scenarios where the “cost” camp might be right?
Ledgers
So much comment in this space talks about “distributed ledgers” or “decentralized ledgers”. But there is very little reflection on what we actually mean by “ledger”.
Investopedia has a good definition of a General Ledger:
A company’s main accounting records. A general ledger is a complete record of financial transactions over the life of a company. The ledger holds account information that is needed to prepare financial statements, and includes accounts for assets, liabilities, owners’ equity, revenues and expenses.
There are some key points here: “complete record of financial transactions”… “information that is needed to prepare financial statements”. I find this a useful definition because it captures two insights that will become important.
- first, we use ledgers to record facts… things that the company has done, transactions it has entered in to.
- second, the ledger is not an end-product; rather, it’s something from which we prepare other documents – our balance sheet, for example.
A worked example
So let’s work through an example of a balance sheet to test the “cost” argument.
In what follows, I’ll work through a really simple and not-representative example that constructs a balance sheet for a small firm – and asks if there are any opportunities to apply decentralized consensus technology to the problem. (And, as will become painfully clear, I’m not an accountant…)
The world’s smallest and most naïve investment bank…
Imagine you had a fetish for being regulated and decided to start your own TINY investment bank. You persuaded your friends and family to invest £1m and opened the company. You haven’t started trading yet so your accounts are really simple: you have put the £1m you raised in the bank (let’s say Barclays) and, since your friends and family own the firm, you also have £1m of equity – which represents their ownership of the firm. Let’s call it RichardCo.
Hang On – What’s a Balance Sheet?
In my mental model, a Balance Sheet is the financial statement you use as a snapshot of the firm’s financial position at a point in time:
- What are all the things you owned at that point (your assets)?
- And what are all the things you owe (your liabilities?).
- If the difference is positive, great: this is your shareholders’ equity in the business. If it’s negative, it’s game over: you’re insolvent.
So the “balance sheet” for RichardCo on day one might look like this:
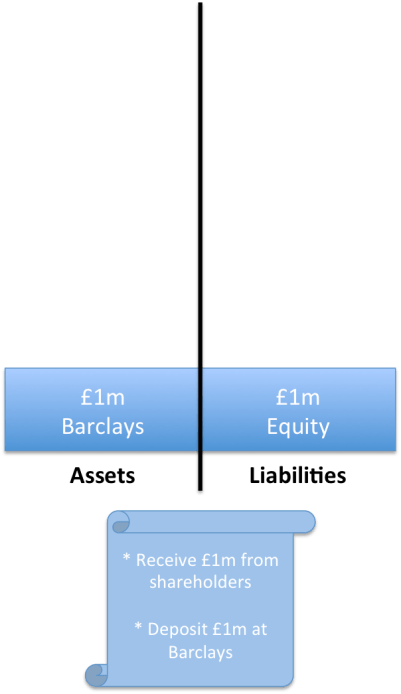
RichardCo’s simple balance sheet. There’s £1m in the bank and you record your shareholders’ funds on the liability side of the balance sheet. The “scroll” is the ledger.
By convention, we put the assets (the things you own) on the left and the liabilities (the things you owe) on the right. And we’ve captured a couple of likely entries from various ledgers that explain where the entries on the balance sheet came from.
Notice how we put the shareholders’ funds (the equity) on the “liabilities” side of the balance sheet. This is because the shareholders’ funds can be thought of as a “residual claim” on the company. If you shut it down (or were shut down), you’d have to sell the assets, use the proceeds to pay off everybody you owed money to and, whatever was left, would be the shareholders’. You’d be liable to pay it to them. So we think of the equity as a liability.
Now, like I say, we haven’t done any business yet. But, already, there’s some complexity here
Think about that £1m in cash. It appears on your balance sheet as an asset and you’ll have a record somewhere recording its receipt from your shareholders and another recording the fact that you paid it into the bank. (Actually, you’ll be using double-entry book-keeping and so you will have four entries in the ledger but let’s leave that to one side for now)
Now think about it from the bank’s perspective. They will also have a record. After all, they took it in as a deposit. So it will also appear on their balance sheet – but this time as a liability. They owe it to you.
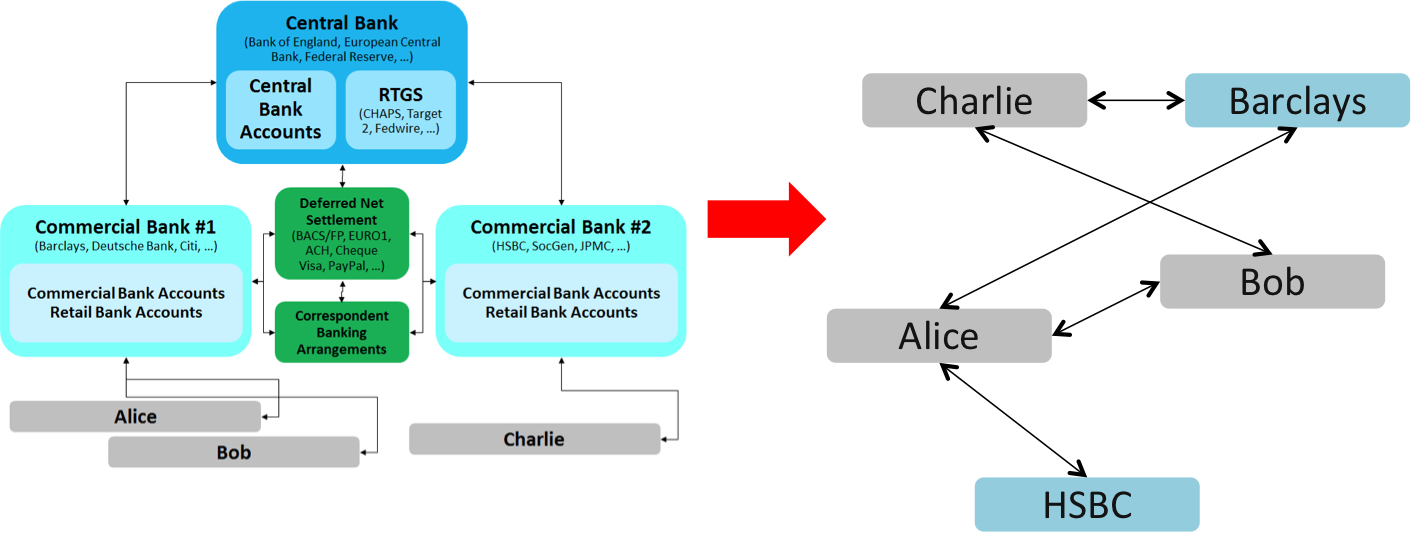
So there are multiple ledgers in two different organisations all recording the same pieces of information and two balance sheets that reflect the position:
- Your balance sheet, recording the claim against Barclays: an asset
- Barclays’ balance sheet, recording their obligation to you: a liability
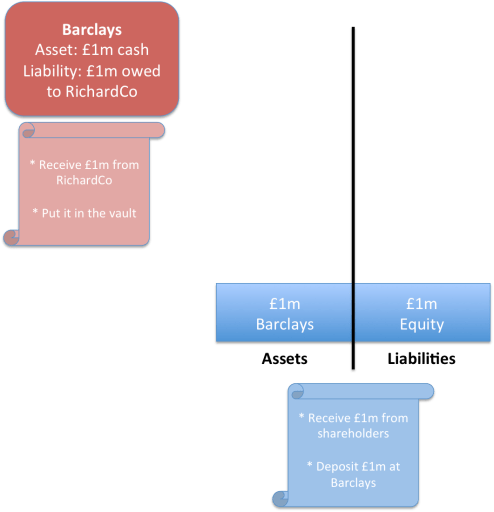
Your £1m asset in the bank also appears on the bank’s balance sheet, as a liability.
Great – this is as it should be and it makes it possible for us to keep an eye on things. When it’s time to get your accounts audited, the auditor doesn’t just have to trust your ledgers. They can phone up the bank and get them to verify that their recording of the position matches yours. The fact you know this can happen acts as a disincentive to cheat in the first place.
If only banks really were this simple…
But, in reality, it’s far more complex than this.
In reality, banks aren’t funded primarily by equity… they also have a HUGE amount of debt…
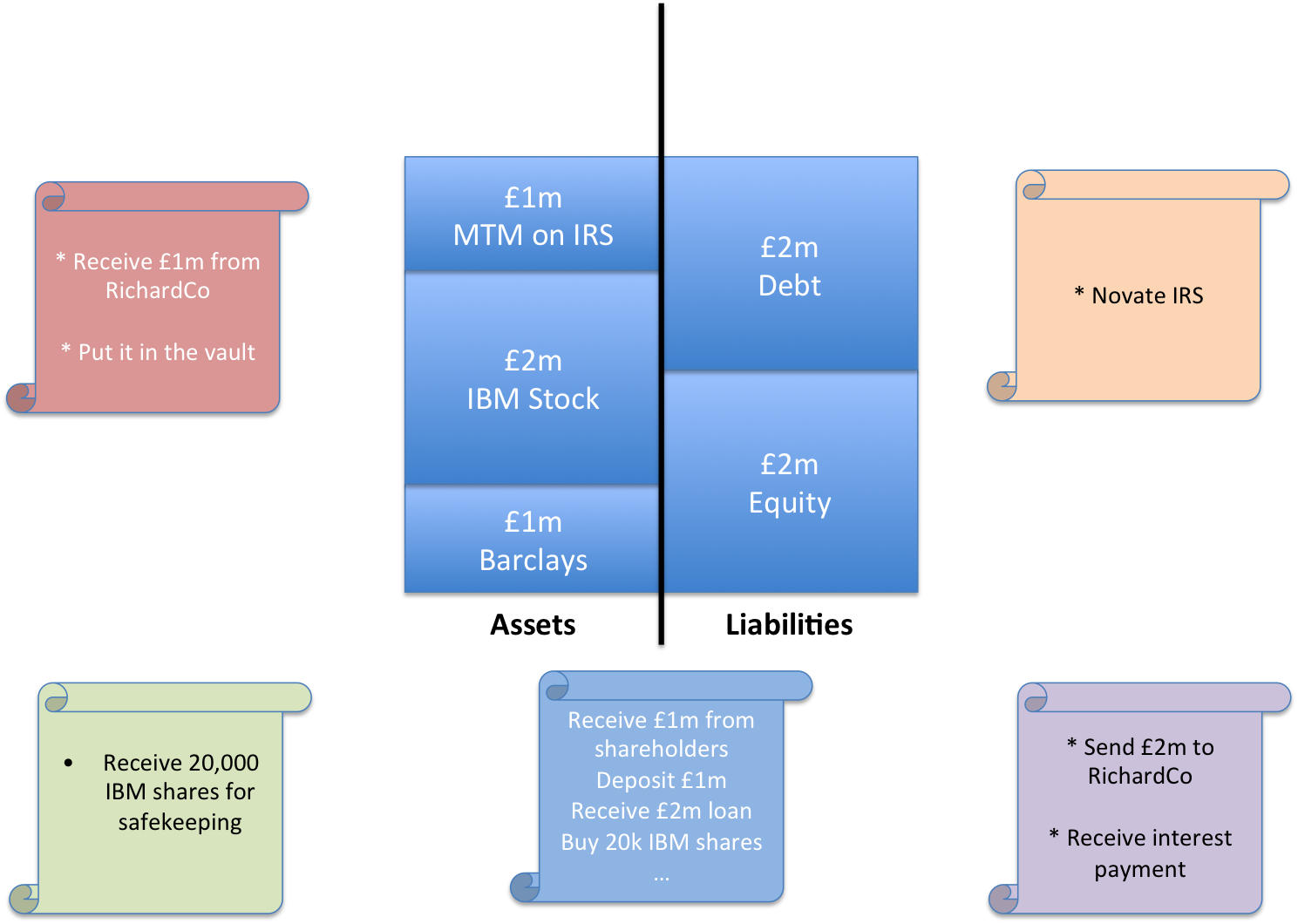
So let’s imagine you have gone to some pension funds and borrowed £2m – you want to be prudent for now.
Youou decide to build out your broker-dealer arm first so you use the money you borrowed to buy some shares for inventory: £2m of IBM stock. That gets you about 20,000 shares, which you deposit at a custodian bank for safekeeping.
Let’s also imagine that you enter into some interest rate swaps with some other banks. Perhaps LCH.Clearnet, acts as central counterparty for all these trades. And, brilliant news! Your derivatives positions have moved in your favour and it looks like you’re up £1m on them!
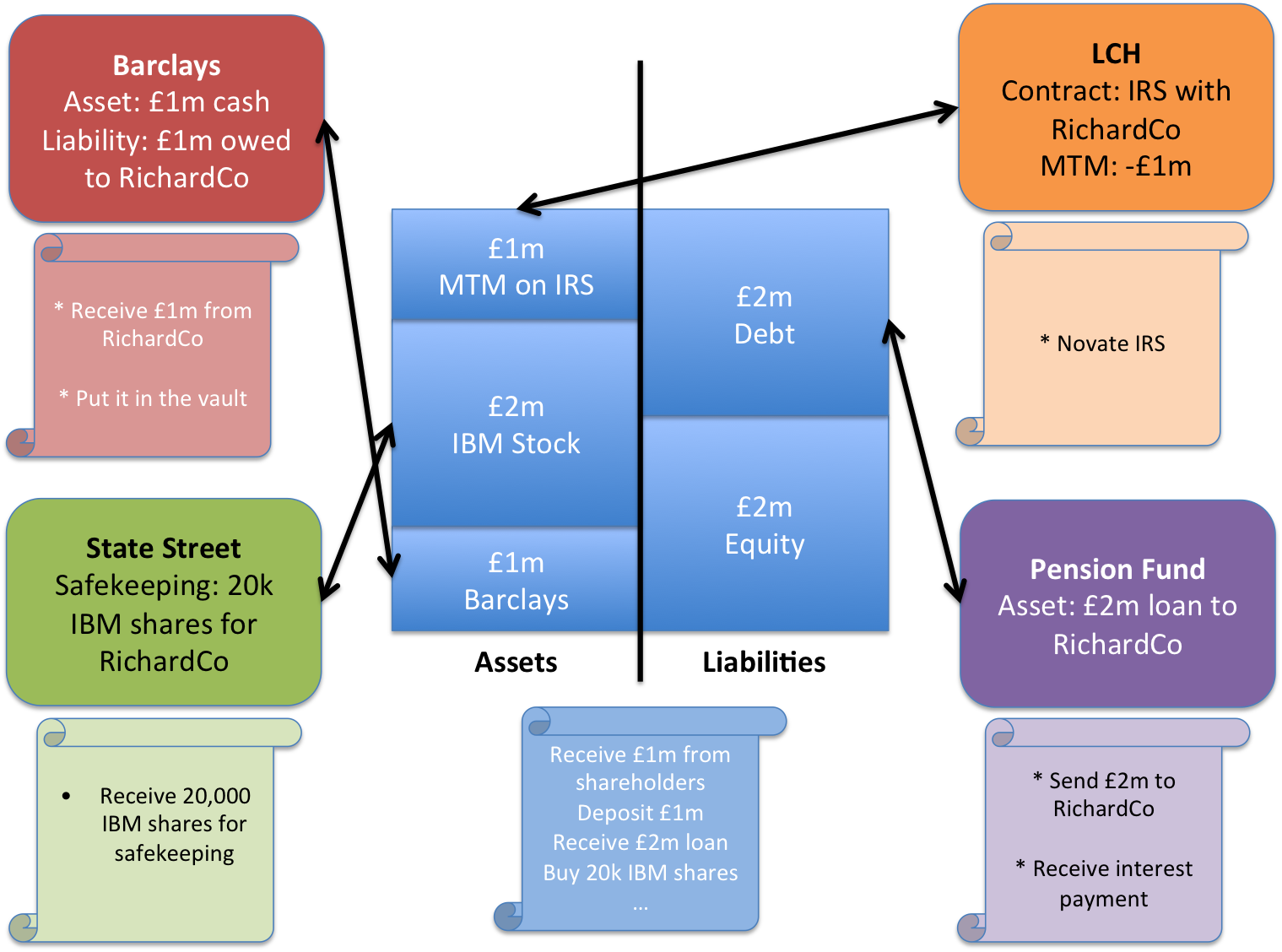
Great. So your balance sheet now looks like this.

Your balance sheet after borrowing £2m, entering into some derivatives contracts that move in your favour (£1m mark-to-market – MTM) and buying some IBM shares. Notice how Shareholders’ Funds (equity) has increased by £1m as your assets (the money owed to you by LCH) have increased in value, whilst your debt has stayed the same.
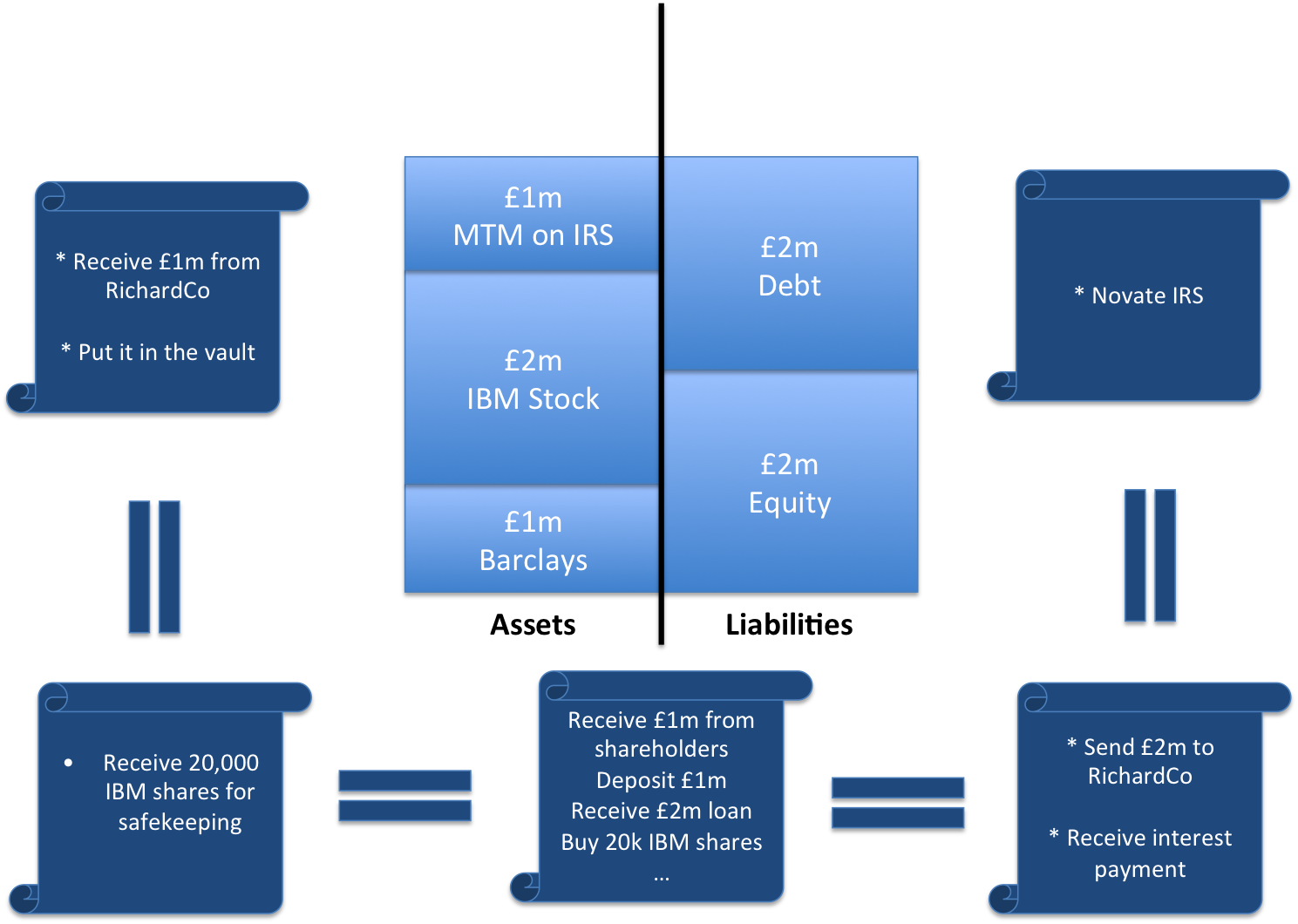
Now think about all the book-keeping at all the other firms
For every position on your ledgers that goes into creating this balance sheet, at least one other entity will also have a ledger that records the same position (from their perspective).
So you might end up with a picture like this:
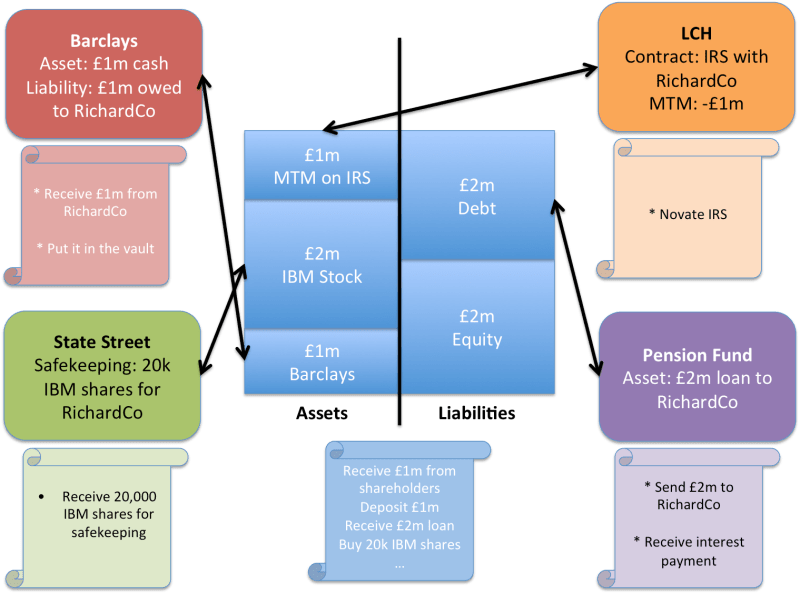
Your (still very simple!) balance sheet will be reflected on ledgers and balance sheets all across the financial system.
And this picture isn’t the full story. Remember we said the clearing house stepped in and became your counterparty? So the other participants will, in turn, have their own ledgers on the other side of the clearing house. And your shareholders presumably have their own records. And so on.
Making sure all these ledgers are kept in sync: reconciliation
One of the many important control functions in a bank is to check regularly that all these ledgers line up – that your counterparties agree with you on what it is that each of you own or owe to each other.
But, interestingly, you only really need to agree your positions – not the valuations. You could, quite legitimately, come to different conclusions about the value of some positions. For example, let’s imagine that the pension fund thinks there’s a chance you’ll default on your loan. They will still have a record that you borrowed £2m but they may only value the position on their balance sheet as a £1.9m asset.
This is an interesting subtlety: the fact, as shown on the ledger, is that you owe £2m but the pension fund’s balance sheet may reflect their opinion that they’ll likely only recover £1.9m
Similarly, the fact of your derivatives positions is recorded on your (and LCH’s) ledgers. And you’ve probably agreed to pay (or receive) whatever cashflows their systems calculate. But how you value your overall position on the balance sheet could depend on a whole other set of factors.
So perhaps the picture actually looks like the one below: the “facts” that we need to reconcile between firms are those contained on the underlying ledgers, not the subjective valuations on the balance sheets:
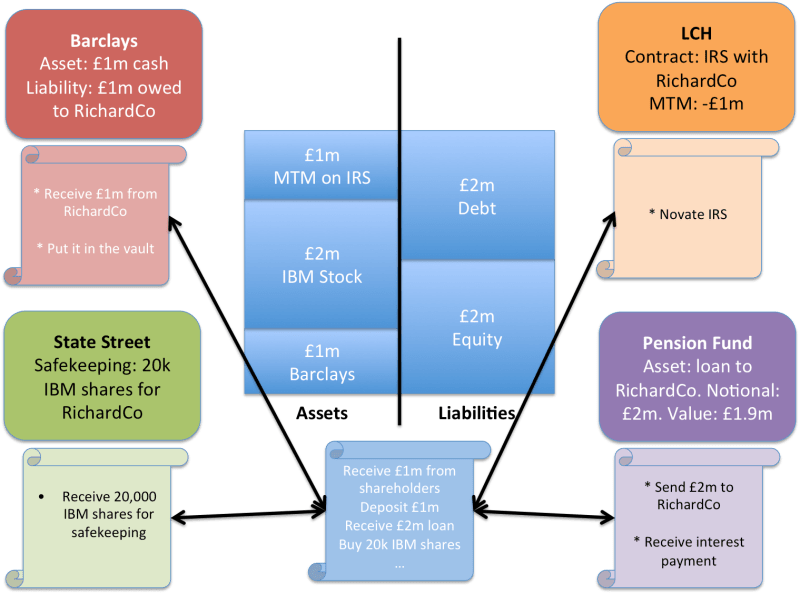
In principle, we need to reconcile our ledgers to keep everybody accurate and honest. But it’s perfectly OK for the subjective valuations of some of the positions (as reflected on the balance sheets) to be different – such as with the pension fund here.
So, to simplify hugely, we could say that our problem is one of keeping all these disparate ledgers in sync:
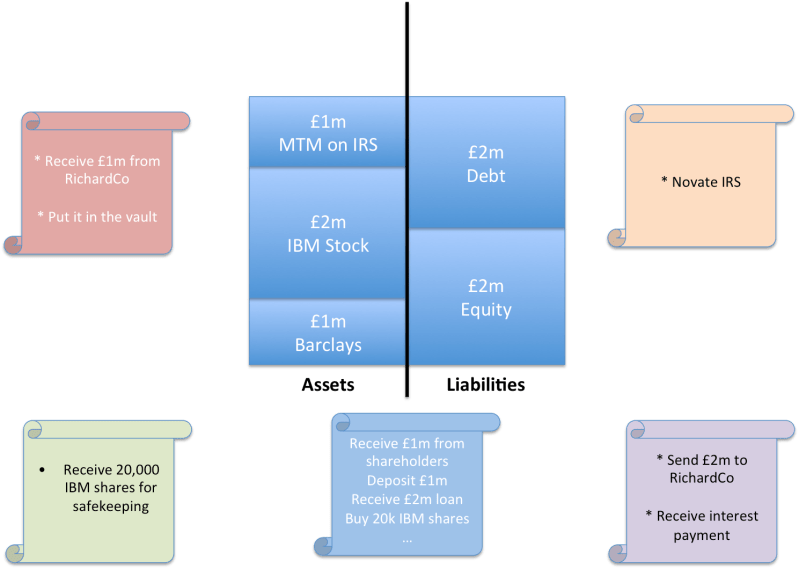
The same picture as before but with the other firms’ balance sheets removed for clarity. Our problem is to make sure these ledgers always agree with each other when they record information about the same transactions.
So we see in the picture above that the facts that underpin my view of the world need occasionally to be checked against at least four other ledgers in other organisations and, in reality, many more.
Enter Decentralised Ledgers
So now let’s turn attention back to the world of decentralized consensus.
I said earlier that it’s hard to argue a decentralised ledger system like Bitcoin that replicates ledger data thousands of times can be more efficient. But perhaps it (or something like it) can.
Imagine we’re living five or ten years in the future. Perhaps we have a securities block chain that records ownership of all securities in the world. Perhaps we have a derivatives smart contract platform that records (and enforces?) all derivatives contracts? Maybe, even, there will be a single, universal platform of this sort.
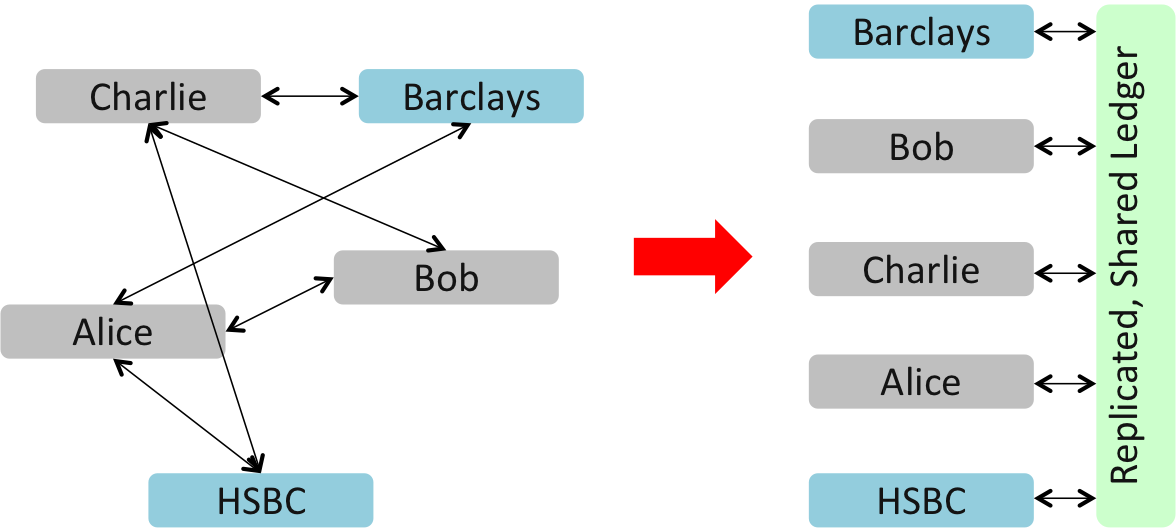
If so, perhaps all participants would have a full copy of this ledger. And so now maybe we can redraw the picture.
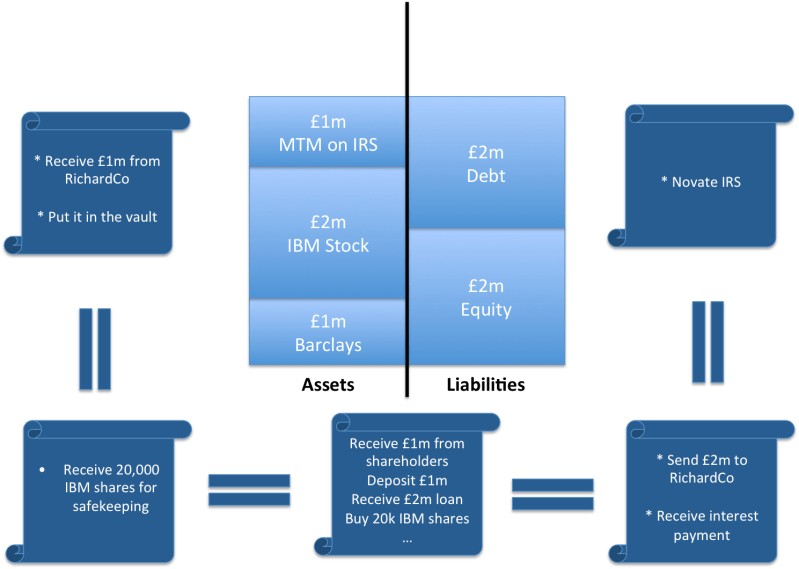
A possible future: all firms record their external obligations and claims on a single shared, massively replicated ledger. Would this reduce (remove?) the need for systems duplication and reconciliation?
Sure – everybody still has a copy of the data locally… but the consensus system ensures that we know the local copy is the same as the copy everywhere else because it is the shared consensus system that is maintaining the ledger. And so we know we’re producing our financial statements using the same facts as all the other participants in the industry.
Does this mean we no longer need audit? No longer need reconciliations? Obviously not, but perhaps this approach is what is driving some of the interest in this space?
But notice: this is just a way of ensuring we agree on the facts: who owns what? Who has agreed to what? We can still run our own valuation algorithms over the top and we could even forward the results to the regulator (who could also, of course, have a copy of the ledger) so they can identify situations where two parties have very different valuations for the same position, which is probably a sign of trouble.
Of course, this is a very simplified example and the real-world is considerably more complex. In particular, some really difficult problems stand in the way of making this a reality:
- Scale – think about how many transactions would be recorded
- Security – imagine what would happen if somebody managed to subvert the ledger. This also has implications for who controls it, runs it and is allowed to connect to it. Bitcoin’s pseudonymous consensus system is unlikely to be appropriate here?
- Privacy – do you really want everybody being able to see all your positions?
- … and so on.
So I’m really not saying this is how things will pan out but I think it’s a useful thought experiment: it shows a potential use for replicated ledgers that might have utility but which doesn’t depend on being “trust-free” or “censorship-resistant”.
Perhaps this is what some of the other commentators in this space have in mind?