UPDATE: The Corda introductory whitepaper is now available! And this blog post gives more context.
As reported in Bloomberg this morning, I’m delighted to confirm that R3 and our member banks are working on a distributed ledger platform for financial services: Corda™. I explain it on our official R3 blog and reproduce it here.
For the last six months, my team and contributors from our membership have been building a distributed ledger platform prototype from the ground up, specifically designed to manage financial agreements between regulated financial institutions. I am massively excited by the progress our team, led by James Carlyle, our Chief Engineer, and Mike Hearn, our Lead Platform Engineer, are making and I think the time is right to share some details.
Corda: A Distributed Ledger for Recording and Managing Financial Agreements
Corda is a distributed ledger platform designed from the ground up to record, manage and synchronise financial agreements between regulated financial institutions. It is heavily inspired by and captures the benefits of blockchain systems, without the design choices that make blockchains inappropriate for many banking scenarios.
Corda’s key features include:
- Corda has no unnecessary global sharing of data: only those parties with a legitimate need to know can see the data within an agreement
- Corda choreographs workflow between firms without a central controller
- Corda achieves consensus between firms at the level of individual deals, not the level of the system
- Corda’s design directly enables regulatory and supervisory observer nodes
- Corda transactions are validated by parties to the transaction rather than a broader pool of unrelated validators
- Corda supports a variety of consensus mechanisms
- Corda records an explicit link between human-language legal prose documents and smart contract code
- Corda is built on industry-standard tools
- Corda has no native cryptocurrency
Corda’s design is the result of detailed analysis and prototyping with our members and will be open sourced when the code has matured further.
In the remainder of this post, I want to share some insight into our thinking. Why are we building Corda? Why have we made some of the design decisions we have? When will the code be ready for others to examine and build upon? How does this relate to other platforms and projects?
A thought experiment
When I joined R3 from IBM in September 2015, I forced myself to stop and think. The blockchain bandwagon was running at full speed, I’d just been appointed CTO of a project intended to bring blockchains to finance but there was a nagging worry at the back of my mind… how could I avoid falling into the trap of believing all the hype?!
I imagined myself sitting in front of the CIO of one of our member banks some time in the future. I imagined we had naively selected a “blockchain for finance” based on what was popular at the time and widely deployed a range of products and services on top of it. And I imagined we had believed the hype, had suspended our critical faculties and had omitted any engineering. In this imagined scenario, I now found myself facing an angry CIO, who wanted to know why the system I had built had just failed calamitously. Why on earth did I build it the way I did?!
I concluded that an entirely inappropriate answer to that question would be: “because blockchains were cool in 2015”! No. That simply won’t do.
The reality is that solutions based on selecting the design first and then trying to apply it to arbitrary problems never work out well. Every successful project I’ve worked on started with the requirements, not some cool piece of technology, and I was determined to bring that discipline into our work at R3.
Remind me again why a system designed to replace banks is also supposedly their saviour?
And there is a second reason for this caution: the technology and finance industries collectively “decided” some time in early 2015 that “blockchain technology” was somehow the future of financial services.
Indeed, I am one of the most active proponents of precisely that claim. But the reason for blockchain technology’s importance is extremely subtle – and this subtlety is something that most people seem to have missed.
To understand this, we need to look at Bitcoin.
Bitcoin’s architecture, as I have often written, is a marvel. Its interlocking components are one of those rare examples of something so elegant that they seem obvious in hindsight, yet which required a rare genius to create.
But what is often missed is that the cleverest part of Bitcoin isn’t actually its architecture; I think the cleverest part was to articulate the business problem. We don’t tend to think of Bitcoin as being the solution to a “business problem” but it can perhaps be thought of as a wonderfully neat solution to the problem of: “how do I create a system where nobody can stop me spending my own money?” Now, I can’t claim to know the mind of Satoshi and he certainly didn’t write the whitepaper in this way but it triggers a very useful thought-experiment.
In fact, once you write this ‘business problem’ down, the design drops out almost trivially! (Almost…) You want always to be able to spend your own money? Then you can’t have a central point of control. It could be shut down by the authorities. You can’t even have a collection of validators with known identities as they could also be shut down with concerted effort. Very quickly you realise you need a massively replicated consensus system and, if you don’t want to tie actions to real-world identities, you need something like Proof of Work to make the voting work. You work the logic through and pretty much the whole design (the blockchain, the need for mining, block rewards, maybe even the UTXO transaction model, etc., etc.) drops out. Of course, it does push a lot of work onto the users: confiscation of somebody’s bitcoins is easy if you know their private key… but let’s leave that to one side for now.
And this way of looking at it is important because it highlights how Bitcoin’s blockchain can be thought of as the solution to a business problem. Satoshi Nakamoto didn’t wake up one morning wanting to “apply Blockchain to finance”. Blockchain was the tool that was invented to solve a real problem.
So we have a conundrum, right? If that’s the case, then what on earth is the argument that says blockchain has any relevance at all to banking?!
Indeed, last time I checked, banks have the inverse of my Bitcoin problem statement!
What is the defining characteristic of blockchain systems?
So I spent most of October sitting in a dark room (really! This was our first London office… a tiny four-person room in a shared working space in the City of London) questioning some of the most fundamental assumptions about blockchains. What is it exactly that makes them interesting to banks?
Most people had already made the mental leap that the “bitcoin package” was unacceptable as a take-it-or-leave-it deal: proof of work is unnecessary for private deployments, for example. But, as I looked around, all I could see was firms who had accepted everything else… It seemed strange to me that, as an industry, we could tease apart one part of the “blockchain bundle” but then stop there.
I spent several of my earlier, formative years at IBM in a role called “technical sales”. If you’ve ever bought technology from a large IT vendor, you’ll have met somebody like me. We’re the people who visit clients with the sales rep and act as the technical expert: we explain how the product works, make sure we’re proposing the right solution to the client and ensure there is no technical barrier to closing the deal.
A lesson I learned very early in that role was: it doesn’t matter how hard you wish or how many client meetings you schedule or how aggressive the sales rep gets, if you can’t show how your solution is going to solve the client’s business problem then the deal almost certainly won’t close. And those that do are the ones you’ll live to regret…
Fast forward a decade, and as I surveyed the blockchain landscape in October 2015, all I could see was excitable (and vocal!) firms touting solutions that made very little sense to me for the kinds of problems I was trying to solve. I will confess to many moments of self-doubt: maybe they were all sane and I was the mad one..?!
But I ploughed on: even if they are right that a “take it or leave it” blockchain design is the saviour of the financial industry, I’ll be doing our members a favour if I could explain why.
So we started picking away at what can perhaps be called the “blockchain bundle”: the collection of services that blockchains provide to those who use them.
We concluded that a blockchain such as the ones underlying Bitcoin or Ethereum or any of the private variations actually provide at least five interlocking, but distinct, services. And the right approach is to treat them as a menu from which to select and customise… different combinations, in different flavours, for different business problems.
CONSENSUS
The first, and most important, feature of blockchains – and the thing that is probably genuinely new in terms of scale and scope – is that they create a world where parties to a shared fact know that the fact they see is the same as the fact that other stakeholders see:
“I see what you see… and I know that what I see is what you see”
And, critically:
“I know that you know that I know”!
And:
“I know that you know that I know that you know…”
And so on…
And it makes this promise across the Internet between mutually untrusting parties. Sure: consensus systems and replicated state machines have existed for years but consensus systems at Internet scale, between untrusting actors, that work in the face of powerful adversaries? That’s a step forward.
In Bitcoin, the shared facts are things like: “What are all the bitcoin (outputs) that have not yet been spent and what needs to happen for them to be validly spent?”. And the facts are shared between all full node users.
In Ethereum, the shared fact is the state of an abstract virtual computer.
But notice something interesting: there isn’t some law of nature that says the set of people who have to be in consensus is the whole world. Bitcoin just happens to work that way because of its unique business problem. If you don’t have Bitcoin’s business problem then be very wary of those trying to sell you something that looks like a Bitcoin solution.
VALIDITY
The second feature in the “blockchain bundle” is validity. Tightly linked to consensus, this feature is the one that allows us to know whether a given proposed update to the system is valid. It is how we define the rules of the game. What does a valid “fact” look like in the system? What does a valid update to that fact look like?
UNIQUENESS
The third feature in the blockchain bundle is its “uniqueness service”. I can quite easily create two perfectly valid updates to a shared fact but if they conflict with each other then we need everybody who cares about that fact to know which, if either, of those updates we should select as the one we all agree on. The “anti-double-spend” feature of blockchains gives us precisely this service and it’s hugely important.
IMMUTABILITY
The fourth feature in the “Blockchain Bundle” is often, if misleadingly, termed “immutability”: data, once committed, cannot be changed.
This isn’t quite true: if I have a piece of data then of course I can change it. What we actually mean is that: once committed, nobody else will accept a transaction from me if it tries to build on a modified version of some data that has already been accepted by other stakeholders.
Blockchains achieve this by having transactions commit to the outputs of previous transactions and have blocks commit to the content of previous blocks. Each new step can only be valid if it really does build upon an unchangeable body of previous activity.
AUTHENTICATION
The final critical feature in the “Blockchain Bundle” is authentication: every action in the system is almost always associated with a private key; there is no concept of a “master key” or “administrator password” that gives God-like powers. This is quite different to traditional enterprise systems where these super-user accounts are prevalent and petrifying from a security perspective.
So what is the financial services business problem?
So why did I take us through this analysis? Because it gets us to the heart of the distributed ledger domain: the thing that is genuinely new is the emergence of platforms, shared across the Internet between mutually distrusting actors, that allow them to reach consensus about the existence and evolution of facts shared between them.
So if that’s what this is all about, then what are the “shared facts” that matter in finance? What business problem would we need to have for any of this work to be of any use at all?
And this is the light bulb moment and the fundamental insight driving the entire Corda project:
The important “shared facts” between financial institutions are financial agreements:
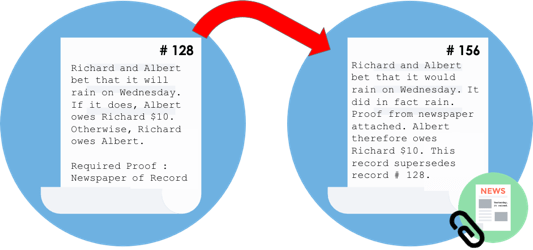
- Bank A and Bank B agree that Bank A owes 1M USD to Bank B, repayable via RTGS on demand.
- This is a cash demand deposit
- Bank A and Bank B agree that they are parties to a Credit Default Swap with the following characteristics
- This is a derivative contract
- Bank A and Bank B agree that Bank A is obliged to deliver 1000 units of BigCo Common Stock to Bank B in three days’ time in exchange for a cash payment of 150k USD
- This is a delivery-versus-payment agreement
- … and so on…
The financial industry is pretty much defined by the agreements that exist between its firms and these firms share a common problem: the agreement is typically recorded by both parties, in different systems and very large amounts of cost are caused by the need to fix things when these different systems end up believing different things. Multiple research firms have postulated that tens of billions of dollars are spent each year on this problem.
In particular, these systems typically communicate by exchanging messages: I send an update to you and just hope you reach the same conclusion about the new state of the agreement that I did. It’s why we have to spend so much money on reconciliation to check that we did indeed reach the same conclusions and more money again to deal with all the problems we uncover.
Now imagine we had a system for recording and managing financial agreements that was shared across firms, that recorded the agreement consistently and identically, that was visible to the appropriate regulators and which was built on industry-standard tools, with a focus on interoperability and incremental deployment and which didn’t leak confidential information to third parties. A system where one firm could look at its set of agreements with a counterpart and know for sure that:
“What I see is what you see and we both know that we see the same thing and we both know that this is what has been reported to the regulator”
That’s Corda.
How does Corda choose from the “Blockchain Bundle” Menu?
So now we understand the financial services requirement, we can look again at the “Blockchain Bundle” menu from above and outline the choices we’ve made.
CONSENSUS
A critical piece of the Corda philosophy is that our problem is to ensure that “I know that you see the same details about a shared fact that I see”.
But this does not mean that a third party down the road also needs to see it: our consensus occurs between parties to deals, not between all participants.
VALIDITY
Furthermore, in Corda, the only people who need to be in agreement about a fact are the stakeholders to that fact: if you and I agree about something that pertains only to us then why should we care what some completely unrelated third party thinks? And why would we even think of sending them a copy so they could opine on it? So, in Corda, we let users write their validation logic in time-tested industry-standard tools and we define who needs to be in agreement on a transaction’s validity on a contract-by-contract basis.
UNIQUENESS
Just like every other distributed ledger out there, we need to be sure that two valid, but conflicting, transactions cannot both be simultaneously active in the system. But we also recognise that different scenarios require different tradeoffs. So Corda’s design allows for a range of “uniqueness service” implementations, one of which is a “traditional blockchain”. But it doesn’t need to be and, for our purposes, we also need implementations that make different tradeoffs under Brewer’s CAP theorem: in particular, some financial services use-cases need to prioritise consistency at the expense of availability in the event of a network partition.
IMMUTABILITY AND AUTHENTICATION
Here, Corda’s design departs very little from existing systems: our data structures are immutable and our building block is the exchange of digitally-signed transactions.
So Corda is very traditional in some respects – we directly apply the “authentication”, “immutability” and “uniqueness service” features of blockchains but we depart radically when it comes to the scope of “consensus” (parties to individual deals rather than all participants) and “validation” (the legitimate stakeholders to a deal rather than the whole universe or some arbitrary set of ‘validators’).
How is Corda Different?
Hang on? Isn’t this the same pitch that every other blockchain firm is making? Not quite.
Notice some of the key things: firstly, we are not building a blockchain. Unlike other designs in this space, our starting point is individual agreements between firms (“state objects”, governed by “contract code” and associated “legal prose”). We reject the notion that all data should be copied to all participants, even if it is encrypted.
Secondly, our focus is on agreements: the need to link to legal prose is considered from the start. We know there will still always be some disputes and we should specify right up front how they will be resolved.
Thirdly, we take into the account the reality of managing financial agreements; we need more than just a consensus system. We need to make it easy to write business logic and integrate with existing code; we need to focus on interoperability. And we need to support the choreography between firms as they build up their agreements.
Different Solutions for Different Problems
But… we should be clear. We are not viewing Corda as a solution to all problems. This model is extremely powerful for some use-cases but likely to be less well suited to others. It’s why we continue to engage extremely deeply with all our partners who are working on complementary platforms in this space; we are not omniscient. Moreover, there are still many significant design and research questions we have to resolve: there is still a great deal of work to do.
Furthermore, I have been deeply impressed by the quality engineering embodied in the many platforms that have passed through our labs and you will continue to hear about projects we are delivering on platforms other than Corda: different solutions for different problems is our mantra. Indeed, those who have attended panels or workshops in recent months will have heard me saying this for some time now.
Corda does not seek to compete with or overlap with what other firms are doing: indeed, we are building it because no other platform out there seeks to solve the problems we’re addressing. That’s what makes this space so endlessly exciting.
What next?
In the coming weeks and months, you’ll hear more about Corda, about our initial projects and about its design. We will also be gearing up to release the core platform as open source, possibly as a contribution to other endeavours. Watch this space.
And… we’re still hiring: there is a great deal of work still to do!












 The whitepaper, which you can download
The whitepaper, which you can download 