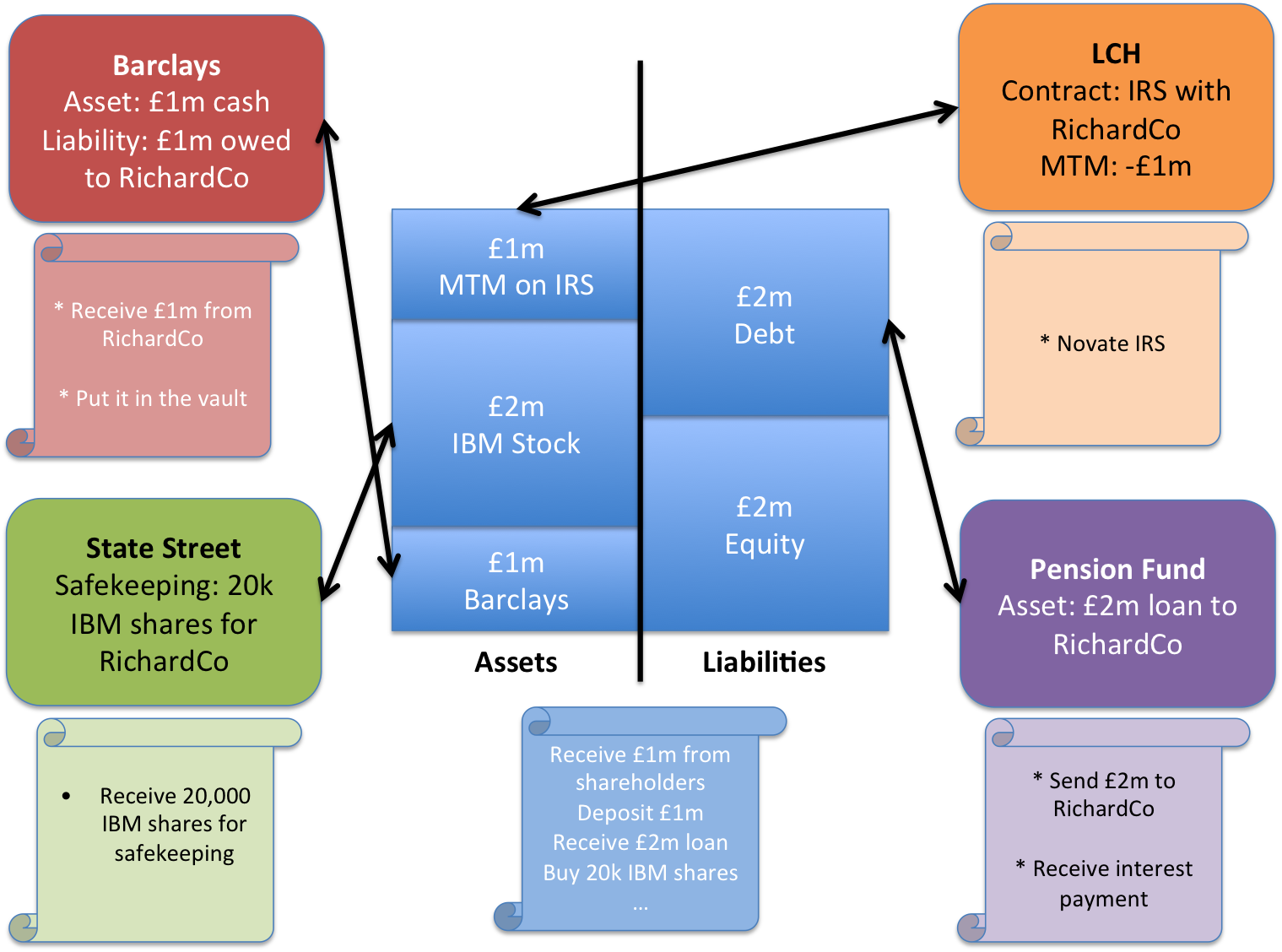
“I just wired you the funds; did you get them?”… “No… I can’t see them. Which account did you send them to? Which reference did you use? Can you ask your bank to chase?”
-

The cheque is in the post…
How can we be almost a fifth of the way through the twenty first century and this is still a daily occurrence? How can we be in a world where even if you and I agree that I owe you some money, it’s still a basically totally manual, goodwill-based process to shepherd that payment through to completion?!
The “Settler pattern” reduces opportunities for error and dispute in any payments process – and does so by changing the process
This was the problem we set out to solve when we built the Corda Settler. And I was reminded about this when I overheard some colleagues discussing it the other day. One of them wondered why we don’t include the recipient of a payment in the set of parties that must agree that a payment has actually been made. Isn’t that kinda a bit of an oversight?!

The Corda Settler pattern works by moving all possible sources of disagreement in a payment process to the start
As I sketched out the answer, I realised I was also describing some concepts from the distant past… from my days in the middleware industry. In particular, it reminded me of when I used to work on Business Process Management solutions.
And there’s a really important insight from those days that explains why, despite all the stupid claims being made about the magical powers of blockchains and the justifiable cynicism in many quarters, those of us solving customer problems with Corda and some other enterprise-focused blockchain platforms are doing something a little bit different… and its impact is going to surprise a lot of people.
Now… I was in two minds about writing this blog post because words like “middleware” and “business process management” are guaranteed to send most readers to the “close tab” button… Indeed, I fear I am a figure of fun amongst some of my R3 colleagues… what on earth is our CTO – our CTO of all people! – doing talking about boring concepts from twenty years ago?!
But, to be fair, I get laughed at in the office by pretty much everybody some days… especially those when I describe Corda as “like an application server but one where you deploy it for a whole market, not just a single firm” or when I say “it’s like middleware for optimising a whole industry, not just one company.”
“Application Servers? Middleware? You’re a dinosaur! It’s all about micro-services and cloud and acronyms you can’t even spell these days, Richard… Get with the programme, Grandad!”
Anyway… the Corda Settler discussion reminded me I had come up with yet another way to send my colleagues round the bend… because I realised a good way to explain what we’re building with Corda – and enterprise blockchains in general – isn’t just “industry level middleware” or “next generation application servers”… it’s also a new generation of Business Process Management platform… and many successful projects in this space are actually disguised Industry Process Re-Engineering exercises.
Assuming you haven’t already fallen asleep, here’s what I mean.
Enterprise Blockchains like Corda enable entire markets to move to shared processes
Think back to the promise we’re making with enterprise blockchains and what motivated the design of Corda:
“Imagine if we could apply the lessons of Bitcoin and other cryptocurrencies in how they keep disparate parties in sync about facts they care about to the world of regular business… imagine if we could bring people who want to transact with each other to a state where they are in consensus about their contracts and trades and agreements… where we knew for sure that What You See Is What I See – WYSIWIS. Think of how much cost we could eliminate through fewer breaks, fewer reconciliation failures and greater data quality… and how much more business we could do together when we can move at pace because we can trust our information”
And that’s exactly what we’ve built. But… and sorry if this shocks anybody… Corda is not based on magic spells and pixie dust… Instead, it works in part because we drive everybody who uses it to a far greater degree of commonality.
Because if you’re going to move from a world where everybody builds and runs their own distinct applications, which are endlessly out of sync, to one where everybody is using a shared market-level application, what you’re actually saying is: these parties have agreed in some way to align their shared business processes, as embodied in this new shared application. And when you look at it through that lens, it’s hardly surprising that this approach would drive down deviations and errors…!
I mean: we’re documenting – in deterministically executed code – and for each fact we jointly care about: who can update which records, when and in what ways. And to do that we have to identify and ruthlessly eliminate all the places where disagreements can enter the process.
Because if we know we have eliminated all areas of ambiguity, doubt and disagreement up-front, then we can be sure the rest of our work will execute as if it’s like a train on rails.
Just like trains, if two of them start in the same place and follow the same track… they’ll end up in the same place at the end.
Reducing friction in payments: a worked example
So, for payments, what are those things? What are those things that if we don’t get them right up front can lead to the “I haven’t received your payment” saga I outlined at the start of the post?
Well, there’s the obvious ones like:
- How much needs to be paid?
- By whom?
- To whom?
- In what kind of money/asset?
There are trickier ones such as:
- Over what settlement rail should I pay?
- To which destination must we pay the money?
- With any reference information?
These are trickier since there is probably a bit of automated negotiation that needs to happen at that point… we need to find a network common to us both… and the format of the routing strings is different for each and so forth. But if you have an ability to manage a back-and-forth negotiation (as Corda does, with the Flow Framework) then it’s pretty simple.
But that still leaves a problem… even if we get all of these things right, we’re still left hanging at the end. Because even if I have paid you the right amount to the right account at the right time and with the right reference, I don’t know that you’ve received it.
And so there’s always that little bit of doubt. Until you’ve acknowledged it you could always turn around in the future and play annoying games with me by claiming not to have received it and force us into dispute… and we’d be back to square one! We’d be in exactly the same position as before: parties who are not in consensus and are instead seeing different information.
And it struck us as a bit mad to be building blockchain solutions that kept everybody in sync about really complicated business processes in multiple industries, only for the prize to be stolen from our grasp at the last moment… when we discover the payment that is invariably the thing that needs to happen at the end of pretty much every process hasn’t actually been acknowledged.
It would be as if our carefully tuned train had jumped off the rails and crashed down the embankment just at the last moment. Calamity!
So we added a crucial extra step when we designed the Corda Settler. We said: not only do you need to agree on all the stuff above, you also need to agree: what will the recipient accept from the sender as irrefutable proof that the payment has been made?
And with one bound, we were free!
Because we can now… wait for it… re-engineer the payment process. We can eliminate the need for the recipient to acknowledge receipt. Because if the sender can secure the proof that the recipient has already said they will accept irrefutably then there is no need to actually ask them… simply presenting them with the proof is enough, by prior agreement.
And this proof may be a digital signature from the recipient bank, or an SPV proof from the Bitcoin network that a particular transaction is buried under sufficient work… or whatever the relevant payment network’s standard of evidence actually is.
But the key point is: we’ve agreed it all up front and made it the sender’s problem… because they have the incentive to mark the payment as “done”. As opposed to today, where it’s the recipient who must confirm receipt but has no incentive to do so, and may have an incentive to delay or lie.
But building on this notion of cryptographic proof of payment, the Corda Settler pattern has allowed us to identify a source of deviation in the payment process and moved it from the end of the process, where it is annoying and expensive and makes everybody sad… and moved it to the start of the process and, in so doing, allows us to keep the train on the rails.
And this approach is universal. Take SWIFT, for example. The innovations delivered with their gpi initiative are a perfect match for the payment process improvements enabled by the Settler pattern.
The APIs made available by Open Banking are also a great match to this approach.
Middleware for markets, Business Process Management for ecosystems, Application Servers for industries..!
And this is what I mean when I say platforms like Corda actually achieve some of their magic because they make it possible to make seemingly trivial improvements to inter-firm business processes and, in so doing, drive up levels of automation and consensus.
So this is why I sometimes say “Corda is middleware for markets”.
It’s as if the first sixty years of IT were all about optimising the operations of individual firms… and that the future of IT will be about optimising entire markets.